


5.2 Aufgaben und Konzepte
Dieser Abschnitt geht näher auf die eingangs skizzierten Hauptaufgaben eines Betriebssystems ein. Hier lernen Sie nicht, wie Sie mit einem bestimmten Betriebssystem arbeiten können (das steht in den nächsten drei Kapiteln), sondern Sie erfahren, was »unter der Haube« vorgeht.
In den folgenden Abschnitten wird jedes wichtige Konzept zunächst allgemein und theoretisch vorgestellt. Anschließend wird skizziert, wie zwei verbreitete Betriebssysteme das jeweilige Problem lösen: Linux und Windows. Für einige der dargestellten Sachverhalte sind Programmierkenntnisse von Vorteil, auch wenn in diesem Kapitel kein Quellcode enthalten ist. Wenn Sie mit der Programmierung überhaupt noch nicht vertraut sind, sollten Sie zunächst Kapitel 9, »Grundlagen der Programmierung«, und Kapitel 10, »Konzepte der Programmierung«, lesen.
5.2.1 Allgemeiner Aufbau von Betriebssystemen
Die Überschrift dieses Abschnitts ist eine recht kühne Übertreibung. Sie enthält ein Versprechen, das niemand einhalten kann: Selbstverständlich gibt es gar keine allgemeine Art und Weise, wie Betriebssysteme aufgebaut sind. Die verschiedenen Systemfamilien unterscheiden sich gerade durch ihren recht andersartigen Aufbau.
Dennoch soll kurz skizziert werden, aus welchen Bestandteilen Betriebssysteme aufgebaut sind beziehungsweise sein können, bevor in den folgenden Abschnitten auf die einzelnen Aufgaben eingegangen wird. Gewisse Grundbestandteile besitzt tatsächlich jedes Betriebssystem, denn alle Systeme müssen Computer verwalten, die bestimmte Gemeinsamkeiten aufweisen.
Beinahe jedes neuere Betriebssystem besteht aus dem Kernel, den mehr oder weniger fest zu diesem gehörenden Gerätetreibern, den Systemprogrammen, einer Schnittstelle für Anwendungsprogramme und einer Benutzeroberfläche.
Der Kernel
Der Kernel (das englische Wort für »Kern«, beispielsweise ein Obstkern) ist das grundlegende Computerprogramm, das unmittelbar auf dem Prozessor des Rechners ausgeführt wird. Er läuft bis zum Herunterfahren des Systems permanent im Hintergrund und steuert alle anderen Betriebssystemkomponenten sowie den Start und den Ablauf der Anwendungsprogramme. Der Kernel initialisiert die Zusammenarbeit mit der Hardware, indem er die Treiber lädt und koordiniert. Aus einer technischen Perspektive können Sie sich vorstellen, dass der Kernel das einzige echte Programm ist, das permanent ausgeführt wird, während alle anderen Programme, die später geladen werden, nur Unterprogramme sind, die vom Kernel aufgerufen werden und die Kontrolle durch einen Rücksprung wieder abgeben.
Es gibt verschieden konzipierte Kernels. Das ältere Kernelkonzept ist der sogenannte monolithische Kernel, der so viel Funktionalität wie möglich selbst erledigt. Moderner ist das Konzept des Mikrokernels, der so wenig wie möglich selbst tut und die meisten Aufgaben an Prozesse delegiert, die im Benutzermodus laufen wie gewöhnliche Anwendungsprogramme.
Da Mikrokernels kleine und elegante Programme sind und da sie die einzelnen Teile des Betriebssystems nur bei Bedarf im Speicher halten, müssten Betriebssysteme auf Mikrokernel-Basis theoretisch schneller und effizienter laufen als Systeme mit monolithischen Kernels. Allerdings wird dabei oft vergessen, dass der ständige Wechsel zwischen Benutzer- und Kernelmodus Zeit und Ressourcen verbraucht. Außerdem können auch monolithische Kernel inzwischen häufig von einem der entscheidenden Vorteile des Mikrokernels profitieren: Die meisten Gerätetreiber sind modular, können also je nach Bedarf geladen und wieder aus dem Speicher entfernt werden. Dies ist besonders wichtig für Hot-Plugging-fähige Schnittstellen wie USB, FireWire oder Bluetooth.
Ein weiterer Fortschritt ist das Threading-Modell, das in immer mehr Betriebssystemen zum Einsatz kommt. Die schwerfälligen Prozesse werden durch eine leichtgewichtige Alternative namens Threads ergänzt, was die Arbeit des Kernels weiter beschleunigt.
Anfang der 90er-Jahre schienen die Mikrokernel sich allmählich durchzusetzen, es wurden um diese Zeit kaum noch völlig neue Betriebssysteme auf der Basis eines monolithischen Kernels konzipiert. Eine wichtige Ausnahme ist Linux – sein Kernel ist bis heute monolithisch, verwendet aber modulare Gerätetreiber und inzwischen auch Threads. Andrew Tanenbaum, der Entwickler von Minix und Autor mehrerer brillanter Fachbücher über Betriebssysteme und andere Informatikthemen, verfasste aus diesem Grund in der Minix-Newsgroup einen berühmt gewordenen Beitrag mit dem Titel »Linux is obsolete« (»Linux ist überholt«).[Anm.: Unter http://oreilly.com/catalog/opensources/book/appa.html können Sie die gesamte Diskussion zwischen Tanenbaum und Torvalds aus der Newsgroup nachlesen.] Inzwischen gehört Linux allerdings zu denjenigen Systemen, die in seinem Lehrbuch »Moderne Betriebssysteme« als Anschauungsbeispiele dienen.
Ein wichtiges Betriebssystem mit Mikrokernel, und zwar dem bekannten Mach-Mikrokernel, ist Mac OS X. Die meisten anderen Unix-Systeme besitzen dagegen wie Linux einen monolithischen Kernel. In gewisser Weise lässt sich der Kernel von Windows NT und seinen Nachfolgern auch als Mikrokernel beschreiben.
Wenn ein Computer eingeschaltet wird, führt das BIOS des Rechners zunächst einige Überprüfungen durch und übergibt die Kontrolle anschließend dem Bootloader eines Betriebssystems. Dieser Teil des Systemstarts wurde bereits in Kapitel 3, »Hardware«, beschrieben. Der Bootloader ermöglicht entweder die Auswahl mehrerer Betriebssysteme, die auf den Datenträgern des Rechners installiert sind, oder startet unmittelbar ein bestimmtes System. Das Booten (kurz für Bootstrapping – die »Stiefel schnüren«) eines Betriebssystems bedeutet zunächst, dass der Kernel geladen und ausgeführt wird. Dieser erledigt alle weiteren erforderlichen Aufgaben.
Wichtig ist es, die bei den meisten Betriebssystemen (insbesondere Unix und Windows) zu beobachtende Trennung zwischen Kernelmodus und Benutzermodus zu verstehen. Ein Prozess, der im Kernelmodus läuft, besitzt gewisse Privilegien, die im Benutzermodus nicht gegeben sind. Bei den meisten Computern werden für die beiden Modi unterschiedliche Betriebsmodi des Prozessors selbst verwendet. Beispielsweise besitzen Intel-Prozessoren und hiermit kompatible Prozessoren seit dem 386er vier verschiedene Modi, die sich durch einen unterschiedlich starken Schutz vor Interrupts, das heißt Unterbrechungsanforderungen durch Hardware oder bestimmte Programmschritte, unterscheiden. Für gewöhnlich wird der Modus mit dem stärksten Schutz als Kernelmodus und der mit dem geringsten als Benutzermodus verwendet.
Prozesse im Kernelmodus führen wichtige Betriebssystemaufgaben durch, die nicht durch Prozesse im Benutzermodus unterbrochen werden dürfen. Beispielsweise sorgen sie für die eigentliche Verarbeitung von Hardware-Interrupts, das Öffnen und Schließen von Dateien oder die Speicherverwaltung. Auch wenn ein Prozess im Kernelmodus nicht von außen unterbrochen werden kann, kann er freiwillig die Kontrolle an einen anderen Prozess abgeben. In der Regel ruft er den Task Scheduler auf, der ebenfalls im Kernelmodus läuft und für die Verteilung der Rechenzeit an die verschiedenen Prozesse zuständig ist.
Ein Prozess im Benutzermodus kann jederzeit unterbrochen werden, etwa durch einen Hardware-Interrupt, durch einen aufwachenden Kernelprozess oder dadurch, dass er selbst einen Befehl aufruft, der nur im Kernelmodus ausgeführt werden kann. Letzteres sind die sogenannten Systemaufrufe (System Calls), die es Programmierern ermöglichen, die eingebauten Funktionen des Betriebssystems zu nutzen.
Mikrokernelbasierte Betriebssysteme versuchen so gut wie alle Aufgaben im Benutzermodus auszuführen. Der Kernel selbst führt im Wesentlichen nur noch die Prozessverwaltung durch; selbst das Speichermanagement und die Ein-/Ausgabekontrolle finden im Benutzermodus statt. Auf diese Weise kann ein Mikrokernel-System zwar flexibler auf Anforderungen reagieren, muss dafür aber häufiger zwischen Kernel- und Benutzermodus hin- und herschalten, was zusätzliche Performance kostet.
Windows NT und seine Nachfolger (einschließlich Vista, Windows 7 und das neue Windows 8) verwenden einen Mittelweg zwischen Mikrokernel-System und monolithischem Kernelsystem: Gewisse Teile wurden aus dem Kernel ausgelagert und bilden sogenannte Subsysteme, die im Benutzermodus laufen und verschiedene Teilfunktionen anbieten, die kernelartige Aufgaben erledigen. Andere Teile des Betriebssystems laufen dagegen im Kernelmodus.
Es gibt nur noch wenige alte Betriebssysteme, die keine richtige Trennung zwischen Kernel- und Benutzermodus durchführen. Dazu gehört das nicht mehr sehr häufig verwendete MS-DOS in Kombination mit Windows 3.11, der letzten Windows-Version, die kein vollständiges Betriebssystem war. Ein anderes System, auf das diese Aussage zutrifft, wurde dagegen bis Anfang des Jahrtausends hergestellt und dürfte vereinzelt noch verwendet werden: Mac OS bis zur Version 9 (Mac OS X ist dagegen eine völlige Neuentwicklung).
Der auffälligste Unterschied zwischen einem modernen System und solchen altmodischen Betriebssystemen besteht darin, dass Letztere nur das veraltete kooperative Multitasking verwenden – ein Prozess entscheidet selbst, wann er die Kontrolle an das Betriebssystem zurückgeben möchte. Stürzt ein Programm ab, das in einem solchen Prozess läuft, dann ist sehr wahrscheinlich das gesamte Betriebssystem instabil geworden. Das in modernen Systemen eingesetzte präemptive Multitasking entscheidet dagegen selbst, wie lange Prozesse im Benutzermodus die Rechenzeit behalten dürfen, und entzieht ihnen diese bei Bedarf wieder.
Außerdem besitzen veraltete Betriebssysteme kein richtiges Speichermanagement; Prozesse können gegenseitig auf ihre Speicherbereiche zugreifen und diese versehentlich überschreiben.
Weitere Informationen über Aufgaben des Kernels finden Sie in späteren Abschnitten bei den Themen Prozessverwaltung, Speichermanagement und Dateisysteme.
Gerätetreiber
Die Gerätetreiber (Device Drivers) sind spezielle kleine Programme, die sich um die Steuerung einzelner Hardwarekomponenten kümmern. In manchen Betriebssystemen sind Treiber ein fester Bestandteil des Kernels, während sie in den meisten neueren Systemen als Module vorliegen, die sich bei Bedarf laden und wieder aus dem Speicher entfernen lassen.
Es ist eine der schwierigsten Aufgaben für Programmierer, Gerätetreiber zu schreiben. Der Treiber bildet die Schnittstelle zwischen Betriebssystem und Hardware. Er muss die allgemeinen Anforderungen des Betriebssystems an eine bestimmte Geräteklasse in die spezifische Sequenz von Steuerbefehlen umsetzen, die das Gerät eines bestimmten Herstellers versteht, und umgekehrt die Antworten des Geräts wieder in eine allgemein verständliche Form bringen.
Aus der Sicht von Treibern lassen sich zwei grundsätzliche Arten von Geräten unterscheiden: Zeichengeräte (Character Devices oder kurz Char Devices) tauschen Daten mit ihrer Umgebung als sequenzielle Datenströme aus. Die Daten werden also Zeichen für Zeichen nacheinander ausgelesen. Typische Beispiele sind die Tastatur, ein Drucker oder ein Bandlaufwerk. Blockgeräte (Block Devices) stellen sich dagegen ähnlich dar wie der Arbeitsspeicher: Der Zugriff auf den Inhalt des Geräts kann in beliebiger Reihenfolge blockweise erfolgen. Zu den Blockgeräten zählen vornehmlich die meisten Laufwerke wie die Festplatte oder ein CD-ROM-Laufwerk, aber auch zum Beispiel Grafikkarten.
Damit ein Treiber für ein bestimmtes Gerät geschrieben werden kann, muss der Hersteller die Schnittstellen dieses Geräts veröffentlichen. Einige Hersteller wollen dies nicht und bieten stattdessen lieber selbst Treiber für die wichtigsten Betriebssysteme an. Bevor Sie sich ein bestimmtes Gerät anschaffen, müssen Sie also sicherstellen, dass ein Treiber für Ihr Betriebssystem verfügbar ist.
Systemprogramme
Diejenigen Bestandteile des Betriebssystems, die nicht zum Kernel gehören, liegen in der Regel als unabhängige Programme vor, die willkürlich geladen, ausgeführt und wieder beendet werden können. Bei einem Betriebssystem mit Konsolenoberfläche müssen Sie die Namen dieser Programme kennen, weil sie durch Eingabe ihres Namens aufgerufen werden. In einer grafischen Benutzeroberfläche werden sie dagegen hinter den Kulissen automatisch aufgerufen, wenn Sie die entsprechenden Menübefehle aufrufen, auf ein Dateisymbol doppelklicken oder Aufgaben per Drag & Drop erledigen, also durch das Ziehen von Symbolen und ihre Ablage an einer bestimmten Stelle.
Verschiedene Betriebssysteme verfügen über unterschiedlich mächtige Systemprogramme. Unix-Systeme sind mit besonders leistungsfähigen Systemprogrammen ausgestattet, weshalb Unix-Benutzer häufiger als die Anwender anderer Betriebssysteme die Konsole verwenden, obwohl auch Unix-Systeme inzwischen mit sehr überzeugenden grafischen Oberflächen ausgestattet sind.
Bei einem Unix-System können Sie jede beliebige Verwaltungsaufgabe über die Konsole erledigen, während unter Windows einige Werkzeuge nur unter der grafischen Oberfläche zur Verfügung stehen. Aus diesem Grund können Unix-Rechner auch von fern über ein Netzwerk bedient werden. Die Konsole kann über eine Terminalemulation zur Verfügung gestellt werden, ein Programm auf einem anderen Rechner übernimmt also die Funktion eines Terminals. Das einzige System, bei dem Sie Systemprogramme nicht ohne Weiteres direkt aufrufen können, weil es überhaupt keine Konsole besitzt, ist das veraltete Mac OS 9.
Typische Systemprogramme sind beispielsweise Befehle zur Manipulation von Dateien und Verzeichnissen, etwa für das Umbenennen, Löschen oder Kopieren. Außerdem gehören allerlei Steuerungs- und Analysewerkzeuge dazu. Systemprogramme werden in den nächsten drei Kapiteln für die einzelnen Betriebssysteme besprochen.
Verwechseln Sie Systemprogramme übrigens nicht mit den im folgenden Abschnitt besprochenen Systemaufrufen. Letztere werden von Prozessen in Gang gesetzt, die auf Dienstleistungen des Kernels zugreifen müssen. Viele Systemprogramme verwenden letztendlich Systemaufrufe, um ihre Aufgabe zu erfüllen, aber nicht alle. Ebenso wenig sollten Sie Systemprogramme mit den einfachen Anwendungsprogrammen durcheinanderbringen, die mit vielen Betriebssystemen geliefert werden. Ein einfacher Taschenrechner, ein Texteditor oder ein MP3-Player ist kein Systemprogramm, sondern eine Anwendung.
Die Schnittstelle für Anwendungsprogramme
Jedes Betriebssystem bietet Anwendungsprogrammen die Möglichkeit, seine Dienstleistungen in Anspruch zu nehmen. Dies ermöglicht es Programmierern, bestimmte aufwendige und hardwareabhängige Aufgaben an das Betriebssystem zu delegieren. Bei den meisten aktuellen Systemen bleibt ihnen auch gar nichts anderes übrig, weil der direkte Zugriff auf die Hardware durch Anwendungsprogramme verhindert wird.
Um eine Funktion des Betriebssystems zu verwenden, muss ein Programm einen Systemaufruf (System Call) durchführen. Das Betriebssystem reagiert darauf, indem es den aktuellen Prozess unterbricht, den geforderten Systembefehl im Kernelmodus ausführt und dessen Ergebnis an den aufrufenden Prozess zurückliefert.
Unix-Systeme bieten nur verhältnismäßig wenige, dafür aber sehr mächtige Systemaufrufe an. Einige von ihnen sind auf Dateien und andere Ein- und Ausgabekanäle bezogen, beispielsweise create() zum Erzeugen einer neuen Datei, open() zum Öffnen, read() zum Lesen, write() zum Schreiben oder close() zum Schließen. Andere Systemaufrufe beschäftigen sich mit der Prozessverwaltung; zum Beispiel erzeugt fork() einen neuen Prozess als Kopie des bestehenden, kill() sendet Signale an Prozesse, und shmget() fordert das Shared Memory (gemeinsame Speicherbereiche, die sich mehrere Prozesse zum Datenaustausch teilen) an.
Neben den eigentlichen Systemaufrufen basiert jedes Betriebssystem auf der Bibliothek der Programmiersprache, in der es geschrieben wurde. Nach wie vor werden die meisten Betriebssysteme zu großen Teilen in der Programmiersprache C geschrieben (nur einige sehr hardwarenahe Teile des Kernels werden in Assembler verfasst). Aus diesem Grund basiert die Arbeitsweise vieler Systembereiche auf Funktionen der C-Standardbibliothek. Unix, Windows und viele andere Systeme behandeln vieles aus der Sicht von Anwendungsprogrammierern recht ähnlich, weil es mithilfe der entsprechenden Bibliotheksroutinen realisiert wurde.
Ein Beispiel soll an dieser Stelle genügen, um einen Eindruck vom Einfluss der C-Standardbibliothek zu geben (konkret lernen Sie sie in Kapitel 9, »Grundlagen der Programmierung«, kennen): Fast alle Betriebssysteme speichern Datum und Uhrzeit als die Anzahl der Sekunden seit dem 01. Januar 1970, 00:00 Uhr UTC.[Anm.: UTC (Universal Time Coordinated) ist im Prinzip identisch mit der Greenwich Mean Time (GMT), verwendet allerdings keine Sommerzeit. In der UTC ist es eine Stunde früher als in Deutschland, wo die MEZ (Mitteleuropäische Zeit) gilt. Bei Sommerzeit beträgt der Unterschied entsprechend zwei Stunden.] Dieses Datum wird als EPOCH bezeichnet, weil es als der »epochemachende« Erfindungszeitpunkt von Unix gilt. Diese Art der Speicherung von Datum und Uhrzeit ist in der C-Bibliotheksdatei time.h definiert.
Unter Windows gibt es eine äußerst umfangreiche Betriebssystemschnittstelle, die Win32 API. Sie besteht aus Tausenden von Befehlen, von denen allerdings nicht alle echte Systemaufrufe sind. Viele von ihnen sind Bibliotheksfunktionen, die beispielsweise den Zugriff auf die Bestandteile der grafischen Benutzeroberfläche ermöglichen. Win32 steht übrigens für »32-Bit-Windows«, in Abgrenzung zu dem längst untergegangenen 16-Bit-Windows, dessen letzte Version Windows 3.11 war. Alle Privatkunden-Versionen seit Windows 95 und alle professionellen Versionen seit der ersten NT-Version gehören zur Win32-Familie; Windows XP, Windows Vista, Windows 7 und 8 sowie die zugehörigen Server-Versionen sind auch in 64-Bit-Versionen für die neueste Generation der Intel- und AMD-Prozessoren verfügbar.
In Kapitel 10, »Konzepte der Programmierung«, gibt es einen Abschnitt über systemnahe Programmierung. Dort erfahren Sie Näheres über den Einsatz von Systemaufrufen.
Die Benutzeroberfläche
Es gibt zwei grundlegende Arten von Benutzeroberflächen: die Konsole oder Kommandozeile und die grafische Oberfläche. Beide dienen dazu, mit dem Betriebssystem zu kommunizieren und stellen ihre Ein- und Ausgabefähigkeiten auch Anwendungsprogrammen zur Verfügung.
Eine Kommandozeilenoberfläche wird (in Abgrenzung zum Kernel) auch Shell genannt. Wenn Sie die Shell verwenden möchten, müssen Sie zunächst wissen, welche Befehle unterstützt werden und wie sie funktionieren. Zu diesem Zweck hält die Windows-Konsole einen Befehl namens help bereit, der eine Liste aller Befehle mit einer kurzen Beschreibung anzeigt. help BEFEHL zeigt dagegen eine ausführliche Beschreibung eines einzelnen Befehls an. Unter Unix heißt die entsprechende Anweisung man BEFEHL. Das hat übrigens nichts mit dem dummen Klischee zu tun, dass Unix »nur was für Männer« sei – »man« ist einfach die Abkürzung für englisch manual, also Handbuch.
Die unter Windows verwendete Konsole entspricht noch heute weitgehend der Benutzeroberfläche von MS-DOS. Die Befehle, die Sie eingeben können, sind fast alle kompatibel mit den alten DOS-Befehlen. Allerdings wurde inzwischen eine Reihe von Komfortfunktionen eingebaut, die die Arbeit mit der Windows-Kommandozeile erleichtern.
Unix-Shells sind allerdings im Vergleich zur Windows-Shell erheblich komfortabler.
Das liegt natürlich zum Teil daran, dass die zugrunde liegenden Systembefehle, die
Sie aufrufen können, mächtiger sind als die Windows-Konsolenbefehle. Aber auch die
Shell selbst hat mehr Bequemlichkeit zu bieten als unter Windows. Beispielsweise wird
unter Unix schon seit Langem die Eingabevervollständigung angeboten – wenn Sie Befehle
oder Dateinamen eingeben, können Sie die  -Taste drücken, um einen begonnenen Namen zu ergänzen, falls er bereits eindeutig
ist. Microsoft hat dieses Feature erst unter Windows 2000 eingeführt.
-Taste drücken, um einen begonnenen Namen zu ergänzen, falls er bereits eindeutig
ist. Microsoft hat dieses Feature erst unter Windows 2000 eingeführt.
Grafische Benutzeroberflächen gibt es inzwischen für jedes Betriebssystem, und auch unter Linux und anderen Unix-Systemen ist es heutzutage üblich, dass Sie gleich die GUI starten, wenn Sie den Rechner booten. In einer grafischen Oberfläche werden die einzelnen Programme und Dokumente in Fenstern dargestellt, die frei über den Bildschirm verschoben, vergrößert und verkleinert und in einer beliebigen Stapelreihenfolge angeordnet werden können. Mit einer Maus bewegen Sie einen Zeiger über diese Oberfläche und können Menübefehle auswählen, Schaltflächen betätigen oder Symbole verschieben.
Unter Linux können Sie sich eine von vielen verschiedenen grafischen Oberflächen aussuchen. Die grundlegenden Grafikfähigkeiten werden von einer Komponente namens X-Window-Server oder kurz X-Server bereitgestellt, darauf aufbauend läuft ein Window-Manager oder ein moderner, voll ausgestatteter Desktop. Die beiden häufigsten Desktops sind KDE und GNOME (sie werden in Kapitel 7, »Linux«, kurz vorgestellt).
Windows und Mac OS lassen Ihnen dagegen keine Wahl bei der Entscheidung für eine bestimmte GUI, weil sie ein fester Bestandteil des Betriebssystems selbst ist. Selbst einige der elementarsten Programme sind so geschrieben, dass sie diese eine Oberfläche voraussetzen. Beide Hersteller haben ihre grafischen Oberflächen in der neuesten Version ihrer Betriebssysteme modernisiert; Mac OS X verwendet eine elegante Oberfläche namens Aqua, die Windows-8-Oberfläche wird Metro genannt.
Für Mac OS X ist auch ein offizieller X-Server verfügbar, sodass der reichhaltige Bestand X-basierter Software, der für andere Unix-Versionen vorhanden ist, bei Bedarf auch unter Mac OS X zur Verfügung steht. Auch für Windows gibt es übrigens X-Server, allerdings nur von Drittanbietern.
5.2.2 Prozessverwaltung
Jedes moderne Betriebssystem ist in der Lage, scheinbar mehrere Aufgaben gleichzeitig auszuführen. Diese Fähigkeit wird allgemein als Multitasking bezeichnet. Es geht dabei nicht nur um den bequemen Nebeneffekt, dass Sie mehrere Anwendungsprogramme geöffnet halten und zwischen ihnen hin- und herschalten können, sondern vor allem um Aufgaben, die das Betriebssystem im Hintergrund erledigen muss, während Sie nur eines dieser Programme verwenden.
Jede der einzelnen, gleichzeitig stattfindenden Aufgaben wird unter den meisten Betriebssystemen durch einen Prozess realisiert. Einem Prozess stehen aus seiner eigenen Sicht alle Ressourcen des Rechners exklusiv zur Verfügung: die gesamte, ungeteilte Rechenzeit des Prozessors, der vollständige Arbeitsspeicher und der alleinige Zugriff auf sämtliche Ein- und Ausgabekanäle. Es ist Sache des Betriebssystems, die Ressourcen hinter den Kulissen zu verteilen. Ein Prozess, der auf eine Ressource wartet, muss in einen Wartezustand versetzt und später wieder aufgerufen werden.
Dieser Service eines Betriebssystems erleichtert es Anwendungsprogrammierern, sich auf ihre eigentlichen Aufgaben zu konzentrieren. Wenn eine Bedingung eintritt, für die ein bestimmter Prozess nicht zuständig ist, übernimmt das System automatisch die Kontrolle, legt den Prozess schlafen, löst das anstehende Problem und ruft den Prozess anschließend wieder auf.
Stellen Sie sich zur Verdeutlichung dieses Sachverhalts vor, Sie wohnten in einem Haus, in dem es für alle Wohnungen nur einen einzigen Klingelknopf an der Haustür gäbe. Ein Druck auf diesen Knopf würde dafür sorgen, dass es in allen Wohnungen klingelt. In diesem Haus müssten alle Mieter auf das Klingeln reagieren und überprüfen, ob es für sie bestimmt ist.
Ähnlich sähe es auf einem Computer aus, wenn es kein Prozessmanagement gäbe: Jedes einzelne Programm müsste sämtliche Bedingungen überprüfen, die auf dem Rechner eintreten können, und keines könnte sich mehr auf seine Tätigkeit konzentrieren.
Das Unix-Prozessmodell
Besonders gut verständlich ist das Prozessverwaltungssystem von Unix, weshalb es hier näher erläutert werden soll. Für Unix-Prozesse gelten die folgenden Aussagen:
- Jeder Prozess ist durch eine eindeutige, ganzzahlige Nummer gekennzeichnet, seine Prozess-ID (PID).
- Der erste Prozess, der auf dem Rechner gestartet wird, heißt init, hat die PID 1 und erzeugt alle anderen Prozesse direkt oder indirekt.
- Jeder Prozess läuft entweder im Kernelmodus oder im Benutzermodus, und zwar ein für alle Mal. Keiner kann den Modus nachträglich wechseln. Ein Anwendungsprogramm kann niemals selbst einen Prozess starten, der im Kernelmodus läuft – dafür gibt es Systemaufrufe.
- Ein neuer Prozess wird durch einen speziellen Systemaufruf namens fork() erzeugt. Dieser Systemaufruf erzeugt eine identische Kopie des Prozesses, der ihn gestartet hat – der neue Prozess kann sich sogar daran »erinnern«, fork() aufgerufen zu haben. Lediglich die PID ist eine andere. In der Regel wird der neue Prozess anschließend für eine neue Aufgabe eingesetzt.
- Jeder Prozess besitzt einen Parent-Prozess. Dabei handelt es sich um denjenigen Prozess, der ihn aufgerufen hat. Wenn der Parent-Prozess vor dem Child-Prozess beendet wird, wird das Child dem Ur-Prozess init zugewiesen. Auf diese Weise wird sichergestellt, dass Prozesse auch weiterhin einen Parent-Prozess besitzen.
- Wird ein Child-Prozess dagegen beendet, wird er nicht komplett aus dem Speicher und aus der Prozesstabelle entfernt, sondern bleibt mit dem speziellen Status »defunct« (außer Betrieb) als sogenannter Zombie-Prozess bestehen. In diesem Zustand bleiben die Zombies, bis der Parent-Prozess den Systemaufruf waitpid() durchführt; dies wird als Reaping (Ernte) bezeichnet. Auf diese Weise kann der Parent den Exit-Status seiner Child-Prozesse untersuchen.
- Jeder Prozess reagiert auf eine Reihe verschiedener Signale. Diese Signale sind durchnummeriert, in der Praxis werden jedoch symbolische Namen für diese Signale verwendet, die irgendwo in der Betriebssystembibliothek definiert sind. Signale werden mithilfe des Systemaufrufs kill() an einen Prozess gesandt. Der etwas seltsame Name rührt daher, dass das Standardsignal den Prozess auffordert, sich zu beenden, falls kein anderes Signal angegeben wird. Wichtige Signale sind etwa folgende: SIGTERM beendet den Prozess normal, SIGKILL erzwingt einen sofortigen Abbruch, SIGHUP (»Hangup«) weist darauf hin, dass eine Verbindung unterbrochen wurde (etwa eine Netzwerkverbindung), und SIGALRM zeigt an, dass ein Timer-Alarm ausgelöst wurde, den Programmierer wiederum verwenden können, um einen Prozess nach einer definierten Zeit wieder zu wecken.
- Ein Prozess kann jederzeit selbst die Kontrolle abgeben, indem er den Systemaufruf pause() durchführt. In diesem Fall kann er durch ein Signal wieder geweckt werden.
- Prozesse im Benutzermodus können auch von außen unterbrochen und später wieder aufgenommen werden.
Wenn ein Prozess unterbrochen wird, muss der Systemzustand, der derzeit herrscht, gespeichert werden, um ihn bei Wiederaufnahme erneut herzustellen. Dazu gehören vor allem die Inhalte der Prozessorregister und der Flags sowie eine Liste aller geöffneten Dateien. Wenn ein Prozess weiterläuft, findet er die Systemumgebung also genau so vor, wie er sie verlassen hat.
Neben der Prozess-ID besitzt jeder Prozess in einem Unix-System eine User-ID (UID) und eine Group-ID (GID). Diese beiden Informationen sind für die Systemsicherheit wichtig: Die User-ID kennzeichnet den Benutzer, dem der Prozess gehört, die Group-ID die Benutzergruppe. Ein Benutzer ist entweder eine bestimmte Person oder eine vom Betriebssystem definierte Einheit; einer Gruppe können beliebig viele Benutzer angehören. Ein Prozess reagiert nur auf Signale, die von einem anderen Prozess mit derselben UID und GID aus versandt wurden. Die einzige Ausnahme sind die UID und GID 0, die dem Superuser root vorbehalten sind. Dieser spezielle Benutzer darf auf einem Unix-System alles, also auch jeden Prozess beenden, unterbrechen oder anderweitig steuern.
Mithilfe des Befehls ps können Sie sich auf einer Unix-Konsole anzeigen lassen, welche Prozesse gerade laufen. Angezeigt werden die PID, die UID, die GID und der Pfad des Prozesses. Der Pfad ist die genaue Ortsangabe der Programmdatei, die in dem entsprechenden Prozess ausgeführt wird. Die Verwendung von ps und anderen prozessbezogenen Befehlen wird in Kapitel 7, »Linux«, genauer erläutert.
Windows verwendet ein etwas komplexeres Prozessmodell. Vor allem wird ein neuer Prozess durch einen Systemaufruf namens CreateProcess() erzeugt, der keine exakte Kopie des aufrufenden Prozesses erzeugt, sondern einen »leeren« Prozess, dem anschließend eine Aufgabe zugewiesen werden muss. Außerdem ist jeder Prozess im Benutzermodus mit einer numerischen Priorität ausgestattet. Diese entscheidet im Zweifelsfall, welcher Prozess Vorrang hat. Die Liste der laufenden Prozesse können Sie auf der Registerkarte Prozesse des Task-Managers sehen. Hier besteht auch die Möglichkeit, abgestürzte Prozesse zwangsweise zu beenden.
Prozesse haben den Vorteil, dass sie vollkommen voneinander abgeschirmt laufen können: Sie besitzen getrennte Speicherbereiche und können einander nicht in die Quere kommen. Manchmal kann dieser Vorteil jedoch auch ein Nachteil sein, denn mitunter müssen Prozesse miteinander kommunizieren. Eine einfache, aber auf wenige »Wörter« beschränkte Möglichkeit ist die bereits erwähnte Verwendung von Signalen.
Eine andere Option besteht in der Verwendung sogenannter Pipes, die die Ausgabe eines Programms und damit eines Prozesses mit der Eingabe eines anderen verknüpfen. Pipes werden in den Konsolen von Unix und Windows häufig eingesetzt, um die Ausgabe eines Programms durch ein anderes zu filtern, können aber auch aus Programmen heraus geöffnet werden. Beispiele finden Sie in den entsprechenden Abschnitten der nächsten beiden Kapitel; der Einsatz von Pipes in eigenen Programmen wird in Kapitel 10, »Konzepte der Programmierung«, beschrieben.
Die effizienteste Möglichkeit der Kommunikation zwischen Prozessen heißt Inter Process Communication oder System V IPC. Obwohl sie mit System V eingeführt wurde und nicht zum POSIX-Standard gehört, ist sie inzwischen in fast allen Unix-Varianten verfügbar, zum Beispiel auch unter Linux. Im Wesentlichen verwendet die IPC zwei verschiedene Mechanismen: In sogenannte Nachrichtenwarteschlangen (Message Queues) kann ein Prozess schreiben; ein anderer kann sequenziell daraus lesen. Gemeinsame Speicherbereiche (Shared Memory) sind dagegen einfacher zu handhaben: Was ein Prozess in diesem Speicherbereich ablegt, können andere beliebig oft lesen oder ändern.
Deadlocks
Eines der Probleme, die bei der Verwendung mehrerer Prozesse auftreten können, ist eine Situation, in der mehrere Prozesse im Wartezustand gefangen bleiben, weil sie aufeinander oder auf dieselben Ressourcen gewartet haben. Das Wettrennen um den Zugriff auf Ressourcen wird als Race Condition bezeichnet. Zu einem Deadlock (Verklemmung) kommt es, wenn eine solche Race Condition unentschieden ausgeht. Beispielsweise könnten zwei Prozesse in einen Deadlock geraten, weil sie den Zugriff auf ein und dieselbe Datei zu sperren versuchen, um anderweitige Änderungen dieser Datei zu verhindern. Ein Deadlock führt mindestens zum Absturz der betroffenen Prozesse, möglicherweise sogar zum Absturz des gesamten Systems.
Ein gutes Betriebssystemdesign vermeidet Deadlocks durch eine Reihe von Verfahren. Insbesondere reicht das normale Verfahren zum Sperren von Ressourcen nicht immer aus, um Deadlocks zu vermeiden. Das gewöhnliche Sperren einer Datei oder einer Hardwareressource überprüft zunächst, ob die Ressource nicht anderweitig gesperrt ist. Falls sie gesperrt ist, wird der Prozess blockiert und wartet, bis die andere Sperre gelöst ist. Anschließend sperrt der aktuelle Prozess selbst die Ressource, sodass andere Prozesse, die sie ihrerseits sperren möchten, wiederum warten müssen.
Statt dieses Modells sollte eine mehrstufige Anmeldung für die Verwendung von Ressourcen eingesetzt werden:
- Ein Prozess, der eine bestimmte Ressource benötigt, versucht nicht einfach, eine Sperre für diese Ressource zu errichten, sondern überprüft zunächst, ob sie nicht bereits gesperrt ist. Falls doch, gibt er die Kontrolle ab, um nicht aktiv auf das Ende der Sperre warten zu müssen, was Ressourcen kosten würde. Er sollte nach einer gewissen Zeit erneut überprüfen, ob die Ressource noch gesperrt ist.
- Wenn die Ressource frei ist, errichtet der Prozess eine Sperre, die andere Prozesse daran hindert, diese Ressource zu verwenden.
- Nachdem der Prozess die Ressource nicht mehr benötigt, löst er die Sperre und gibt die Ressource dadurch wieder frei.
Threads
Einige Prozesse müssen gemeinsam dasselbe Problem bearbeiten und ununterbrochen miteinander kommunizieren. Dies gilt insbesondere für Prozesse, die nebeneinander im gleichen Anwendungsprogramm laufen. IPC oder andere Methoden der Prozesskommunikation sind zwar möglich, verschwenden aber auf die Dauer Systemressourcen. Interessanter ist eine Prozessvariante, bei der sich mehrere Abläufe von vornherein dieselben Ressourcen teilen.
Zu diesem Zweck werden in vielen Betriebssystemen die leichtgewichtigen und schnell zu wechselnden Threads verwendet. Diese besitzen innerhalb desselben übergeordneten Prozesses keine voneinander getrennten Speicherbereiche, sondern greifen auf dieselbe Stelle des Speichers zu. Windows unterstützt Threads bereits seit den ersten Versionen von Windows NT, in Unix-Systemen wurden sie erst später eingeführt. Zuletzt wurden sie unter Linux nachgerüstet; seit dem Kernel 2.4 können sie als stabil bezeichnet werden.
Threads übernehmen häufig Aufgaben, die parallel innerhalb desselben Programms ausgeführt werden müssen. Besonders anschaulich lässt sich dies anhand eines in Echtzeit laufenden 3D-Computerspiels erläutern: Eingaben zur Steuerung der eigenen Spielfigur müssen gleichzeitig entgegengenommen werden, die Umgebung muss ständig neu gezeichnet werden, und es müssen permanente Zustandskontrollen stattfinden. Es wäre für einen Programmierer ein Ärgernis, wenn er sich selbst Gedanken darüber machen müsste, in welcher Reihenfolge die einzelnen Schritte wann stattfinden sollen. Werden die verschiedenen Aufgaben dagegen in Threads verpackt, führt der Prozessor sie abwechselnd in kurzen Zeitintervallen aus.
Die Verwendung von Prozessen und Threads aus Programmierersicht wird übrigens in Kapitel 10, »Konzepte der Programmierung«, erläutert.
5.2.3 Speicherverwaltung
Eine der wichtigsten Aufgaben eines Betriebssystems besteht in der Verwaltung des fast immer zu kleinen Arbeitsspeichers. So gut wie alle aktuellen Betriebssysteme verwenden eine echte virtuelle Speicheradressierung, bei der die von den Programmen angesprochenen Speicheradressen nicht identisch mit den Hardwareadressen des RAM-Speichers sein müssen.
Genau wie Gerätetreiber und Prozessmanagement entbindet das Speichermanagement einen Programmierer von einer recht frustrierenden Aufgabe, nämlich von der Verteilung des Arbeitsspeichers an die einzelnen Prozesse beziehungsweise Programme. Da eine richtig funktionierende Speicherverwaltung jedem Programm vorgaukelt, ihm stünde der gesamte Arbeitsspeicher zur Verfügung, müssen Sie sich beim Programmieren nicht mehr viele Sorgen machen, ob der Arbeitsspeicher reicht.
In der Regel wird der virtuelle Speicherraum vom Betriebssystem in sogenannte Segmente unterteilt. Bei modernen Computersystemen beherrscht bereits der Prozessor selbst die Speichersegmentierung und kann dadurch mehr Speicher adressieren, als im physikalischen RAM zur Verfügung steht. Zu diesem Zweck enthalten aktuelle Prozessoren ein Bauteil namens Memory Management Unit (MMU). Spricht ein Programm eine bestimmte Speicheradresse an, dann nimmt die MMU sie entgegen und rechnet sie in die aktuell zugeordnete physikalische Speicheradresse um.
Aus der Sicht des Speichermanagements im Betriebssystem wird der Speicher in einzelne Seiten unterteilt, die durch das sogenannte Paging auf die Festplatte ausgelagert werden, wenn ein Programm sie gerade nicht benötigt, und in den Arbeitsspeicher zurückgeholt, wenn es sie wieder braucht. Die Datei, in der sich die ausgelagerten Speicherseiten befinden, wird als Auslagerungsdatei (Page File) bezeichnet. Unix-Systeme verwenden häufig keine einzelne Datei dafür, sondern eine Plattenpartition eines speziellen Typs, die als Swap-Partition bezeichnet wird.
Die MMU unterhält zu diesem Zweck eine Seitentabelle, die zu jedem Zeitpunkt darüber Auskunft gibt, welche virtuelle Speicherseite sich gerade wo befindet, sei es im Arbeitsspeicher oder in der Auslagerungsdatei. Dass eine Speicherseite benötigt wird, die zurzeit ausgelagert ist, wird dabei durch einen Page Fault (Seitenfehler) zum Ausdruck gebracht.
Da das Speichermanagement auf den Fähigkeiten der zugrunde liegenden Hardware aufbaut, funktioniert es unter Windows und Linux, sofern sie auf Intel-Rechnern oder Kompatiblen laufen, recht ähnlich. Auf einem solchen x86-System ist eine Speicheradresse 32 Bit lang – es handelt sich schließlich um einen 32-Bit-Prozessor. Allerdings werden nicht einfach die verfügbaren physikalischen Speicheradressen durchnummeriert. Stattdessen ist die Adresse in drei Bereiche unterteilt (siehe auch Abbildung 5.1):
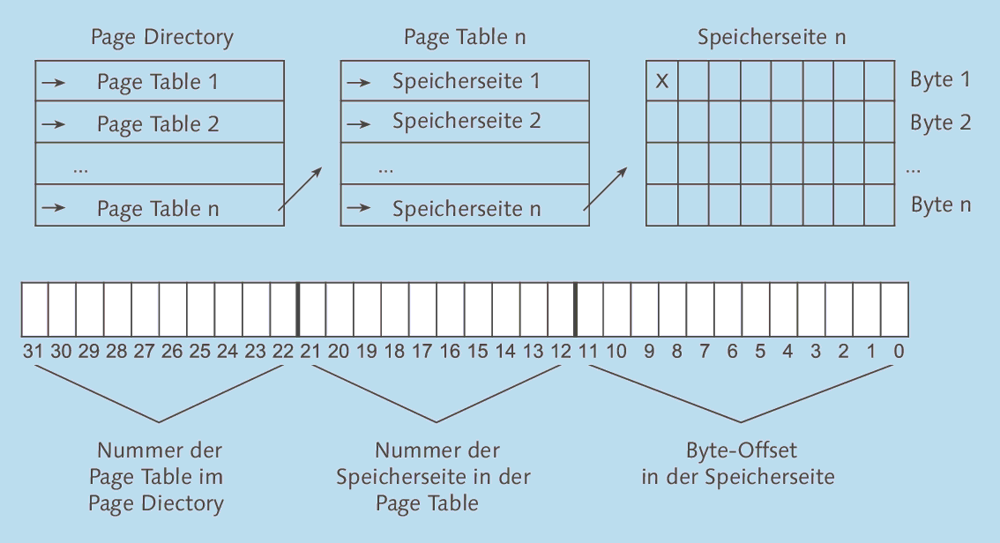
Abbildung 5.1 Schema der x86-Speicherverwaltung
- Die zehn obersten Bits (31 bis 22) geben den Eintrag im Page Directory (Seitenverzeichnis) an, verweisen also auf eine Adresse in einem Speicherbereich, der eine Liste von Seitentabellen enthält.
- Die nächsten zehn Bits (21 bis 12) enthalten die Nummer des Eintrags in der genannten Page Table (Seitentabelle). Dieser Eintrag verweist auf eine einzelne Speicherseite.
- Die letzten zwölf Bits (11 bis 0) geben schließlich den Offset an, das heißt das konkrete Byte innerhalb der Speicherseite. Dies führt dazu, dass eine Speicherseite eine Größe von 212 oder 4.096 Byte besitzt.
Auf diese Struktur der Hardware baut die Speicherverwaltung des Betriebssystems auf. Jedes Programm kann dynamisch mehr Speicher anfordern und erhält ihn, indem zurzeit nicht benötigte Speicherseiten ausgelagert werden. Es kommt daher bei einem modernen System nicht oft vor, dass eine Anwendung wegen Speichermangels abgebrochen werden muss oder gar nicht erst startet. Allerdings wird ein Rechner, der zu wenig physikalischen Arbeitsspeicher besitzt, zu langsam, weil er mehr mit dem Paging beschäftigt ist als mit der eigentlichen Arbeit.
Da sich allmählich 64-Bit-Architekturen durchsetzen, wird auch die Speicherverwaltung entsprechend angepasst. Beispielsweise verwendet Linux schon seit Kernel 2.2 intern ein dreistufiges Paging-Modell: Das Page Directory zeigt nicht gleich auf eine Page Table, sondern zunächst auf ein weiteres Verzeichnis, genannt Middle Directory. Da unter 32-Bit-Architekturen keine Verwendung dafür besteht, wird der Middle-Directory-Eintrag im Page Directory dadurch stillgelegt, dass er immer den Wert 0 besitzt, also immer auf dasselbe vermeintliche Middle Directory zeigt. Da die meisten Linux-Versionen bereits auf 64-Bit-Prozessoren laufen, ermöglicht dieses Vorgehen die Verwendung desselben Speicherverwaltungsmodells für alle Linux-Versionen.
5.2.4 Dateisysteme
Eine der wichtigsten Aufgaben eines Betriebssystems ist die Verwaltung von Dateien. Eine Datei ist eine benannte Einheit, die auf einem Datenträger gespeichert wird. Die verschiedenen Arten von Datenträgern wurden in Kapitel 3, »Hardware«, vorgestellt. Dort erfahren Sie auch, wie die Daten physikalisch auf den Datenträgern organisiert sind.
Die meisten Betriebssysteme sprechen nicht direkt die Hardwaresektoren eines Datenträgers an, sondern unterteilen den Datenträger logisch in größere Abschnitte, die als Zuordnungseinheiten (Cluster) bezeichnet werden. Dies hat den Vorteil, dass das System sich nicht weiter um die tatsächliche Größe des Datenträgers kümmern muss.
Ein gewisser Nachteil besteht dagegen darin, dass jede Datei mindestens eine ganze Zuordnungseinheit belegt und dass eine neue belegt wird, wenn die Datei auch nur um ein Byte zu groß ist – das Verfahren ist vergleichbar mit einem Parkhaus, in dem Sie für »angefangene Stunden« bezahlen müssen: 61 Minuten werden dort bereits als zwei Stunden gewertet. Einige moderne Dateisysteme wie das Linux-eigene ext3 oder ext4 speichern die »überstehenden« Stücke von Dateien, die keine ganze Zuordnungseinheit mehr füllen, deshalb zusammen in einer gemeinsamen Zuordnungseinheit.
Die unterschiedlichen Betriebssysteme verwenden verschiedene Modelle, um Daten auf einem Datenträger abzulegen. Ein solches Modell wird als Dateisystem bezeichnet. Da die meisten Betriebssysteme mit mehreren Dateisystemen umgehen können, verwenden sie eine zweistufige Dateiverwaltung: Das eigentliche Dateisystem greift auf den Treiber für das Laufwerk zu und organisiert die Daten auf dem eigentlichen Datenträger, während ein virtuelles Dateisystem den Zugriff des Betriebssystems auf die verschiedenen tatsächlichen Dateisysteme und Datenträgerarten vereinheitlicht. Unter Unix geht die Abstraktion von Dateien so weit, dass selbst der Zugriff auf Geräte über Special Files (Spezialdateien) oder Gerätedateien erfolgt, die normalerweise im Verzeichnis /dev liegen.
Als Benutzer eines Betriebssystems werden Sie vornehmlich mit dem virtuellen Dateisystem konfrontiert. Hier wird vor allem geklärt, wie die einzelnen Datenträger und Partitionen angesprochen werden, wie Verzeichnisse organisiert sind, welche Zeichen in Dateinamen erlaubt sind, wie lang diese Namen sein dürfen und so weiter.
Das virtuelle Dateisystem, das alle Unix-Systeme miteinander gemeinsam haben, unterstützt außerdem verschiedene Sicherheitsaspekte, insbesondere die Zugriffsrechte für einzelne Benutzer und Gruppen. Windows bietet ähnliche Fähigkeiten, allerdings nur für das Dateisystem NTFS.
»Verzeichnis« oder »Ordner«?
In diesem Kapitel war bisher die ganze Zeit die Rede von Verzeichnissen. Wenn Sie seit weniger als etwa zehn Jahren mit Computern arbeiten und Windows oder Mac OS einsetzen, werden Sie wahrscheinlich eher »Ordner« kennen. Das liegt daran, dass die symbolische Darstellung (das Icon) eines Verzeichnisses auf dem Desktop der GUI eine Aktenmappe (englisch: folder) zeigt, was in den deutschen Versionen als »Ordner« lokalisiert wurde.
In Wirklichkeit finden Sie im Dateisystem immer Verzeichnisse (englisch: directories). Sie sind die Ordnungs- und Organisationseinheiten des Dateisystems.
Das virtuelle Unix-Dateisystem
Die in diesem Buch näher besprochenen Unix-Systeme Linux und Mac OS X haben mit allen anderen Unix-Systemen dasselbe virtuelle Dateisystem gemeinsam. Konkrete Dateisysteme gibt es unter Unix dagegen unzählige. Beispielsweise unterstützt Mac OS X das klassische Apple-Dateisystem HFS+, das Unix-Dateisystem UFS, das CD-ROM-Dateisystem ISO 9660 und andere, während Linux mit seinem eigenen Dateisystem ext3 oder ext4, btrfs, den Windows-Dateisystemen FAT und NTFS sowie mit weiteren zusammenarbeitet.
Die Gemeinsamkeiten der Unix-Dateisysteme betreffen die Art und Weise, wie Dateien, Verzeichnisse und Datenträger organisiert sind. Außerdem sind die Zugriffsrechte für alle unter Unix unterstützten Dateisysteme verfügbar.
Auf einem Unix-Rechner existiert nur ein einziger Verzeichnisbaum, unabhängig davon, auf wie viele konkrete Datenträger er verteilt ist. Die Wurzel des gesamten Baums wird als / bezeichnet. Unterhalb dieses obersten Verzeichnisses liegen einzelne Dateien und Unterverzeichnisse; jedes von ihnen kann wiederum in Unterverzeichnisse unterteilt sein.
Die meisten Verzeichnisse, die direkt unterhalb der Wurzel des Unix-Dateisystems liegen, haben spezielle Aufgaben, die in allen gängigen Unix-Systemen identisch oder zumindest ähnlich sind:
- bin (»binaries«) enthält die Systemprogramme.
- sbin (»start binaries«) enthält Initialisierungsprogramme, die beim Systemstart aufgerufen werden.
- dev (»devices«) enthält Gerätedateien, also Dateien, die auf die einzelnen Hardwarekomponenten verweisen. Der Vorteil dieser Methode ist, dass sich der Zugriff auf Geräte genau wie bei einzelnen Dateien über Benutzerrechte regeln lässt.
- usr (»user«) enthält die wichtigsten Anwendungsprogramme.
- opt (»optional«) enthält zusätzliche Anwendungen, die nicht ganz so häufig benötigt werden.
- etc enthält allerlei Konfigurationsdateien.
- var enthält variable Daten, vor allen Dingen Log-Dateien, in die Systemmeldungen eingetragen werden.
- home enthält für jeden Benutzer, der im System angemeldet ist, ein Home-Verzeichnis. Hier werden alle Anwendungsdaten dieses Benutzers abgelegt. Zusätzlich werden die persönlichen Einstellungen dieses Benutzers für die verschiedenen Anwendungs- und Systemprogramme gespeichert. Unter Mac OS X heißt dieses Verzeichnis übrigens Users.
- root ist das spezielle Home-Verzeichnis des Superusers. Es liegt nicht im Verzeichnis home wie die anderen Benutzerverzeichnisse. home könnte nämlich so eingerichtet werden, dass es auf einem anderen physikalischen Datenträger oder einer anderen Partition liegt als der Rest des Betriebssystems. Möglicherweise steht es also nicht zur Verfügung, wenn ein Fehler auftritt, den root beheben muss.
Der Pfad zu einer Datei wird von der Wurzel aus angegeben, indem die Namen der entsprechenden Ordner jeweils durch einen Slash voneinander getrennt werden. Die folgende Pfadangabe wäre beispielsweise der Pfad einer Datei in meinem Home-Verzeichnis: /home/sascha/fachinformatiker/betriebssysteme.txt.
Da jedes Programm ein Arbeitsverzeichnis besitzt, in dem es mit der Suche nach Dateien beginnt, kann ein Pfad auch relativ angegeben werden, das heißt vom aktuellen Verzeichnis aus. Angenommen, eine Anwendung hat das Arbeitsverzeichnis /home/user und möchte auf die Datei info.txt in /home/sascha zugreifen. Der Pfad dieser Datei kann entweder absolut als /home/sascha/info.txt oder relativ (von /home/user aus) als ../sascha/info.txt angegeben werden. Die Angabe .. spricht jeweils das übergeordnete Verzeichnis an; untergeordnete Verzeichnisse werden einfach mit ihrem Namen angegeben.
»Geschwister«-Verzeichnisse, also nebengeordnete – in diesem Fall user und sascha –, können einander nie direkt ansprechen, sondern müssen mithilfe von ..-Angaben so weit nach oben wandern, bis ein gemeinsamer Vorfahr gefunden wurde. Im Falle von user und sascha müssen Sie nicht weit nach oben gehen; home ist bereits der Elternordner beider.
Eine Abkürzung für das Home-Verzeichnis des aktuell angemeldeten Benutzers ist die
Tilde (~). Sie können durch Angabe der Tilde von überall aus in Ihr Home-Verzeichnis wechseln.
Auf dem PC wird eine Tilde übrigens mithilfe der Tastenkombination  +
+  erzeugt, auf dem Mac müssen Sie zunächst
erzeugt, auf dem Mac müssen Sie zunächst  +
+  betätigen und anschließend die Leertaste drücken: Das Zeichen funktioniert wie ein
Akzent und kann auf ein n gesetzt werden.
betätigen und anschließend die Leertaste drücken: Das Zeichen funktioniert wie ein
Akzent und kann auf ein n gesetzt werden.
Im Übrigen sollten Sie daran denken, dass Unix bei Datei- und Verzeichnisnamen zwischen Groß- und Kleinschreibung unterscheidet. Die Namen hallo.txt, Hallo.Txt und HALLO.TXT bezeichnen drei verschiedene Dateien, die alle im gleichen Verzeichnis liegen könnten. Aus Gründen der Kompatibilität mit alten Macintosh-Anwendungen ist dies ein wichtiger Unterschied zwischen Mac OS X und anderen Unix-Varianten: Auf HFS+-Partitionen unterscheidet Mac OS X nicht zwischen Groß- und Kleinschreibung, auf UFS-Partitionen dagegen schon.
Ein Dateiname, der mit einem Punkt (.) beginnt, wird in der normalen Verzeichnisansicht standardmäßig ausgeblendet (versteckt). Wirkliches Verstecken ist auf diese Weise nicht möglich; effektiver ist die Verwendung von Zugriffsrechten (diese werden in Kapitel 7, »Linux«, genauer besprochen).
Intern werden Dateien auf dem Datenträger nicht durch ihren Namen dargestellt, sondern durch eine ganzzahlige Nummer namens inode. Die Einträge in einem Verzeichnis sind Verweise auf solche inodes. Interessanterweise können mehrere Verzeichniseinträge auf dieselbe inode zeigen. Ein Verzeichniseintrag wird deshalb auch als Hard Link bezeichnet, der fest auf eine bestimmte inode verweist. Eine Datei wird auf einem Unix-System erst gelöscht, wenn Sie alle Einträge im Verzeichnisbaum entfernt haben, die auf die entsprechende inode zeigen.
Im Gegensatz zu den Hard Links werden auch symbolische Links oder Symlinks unterstützt, die nicht direkt auf eine inode zeigen, sondern auf einen anderen Verzeichniseintrag. Anders als die Hard Links können Symlinks auch auf Verzeichnisse verweisen sowie auf Dateien, die auf einem anderen physikalischen Datenträger liegen.
Die verschiedenen Datenträger und Partitionen können übrigens an einer beliebigen Stelle im Verzeichnisbaum eingehängt werden. Dieser Vorgang wird als Mounten bezeichnet. Solange ein Datenträger nicht gemountet ist, können die Verzeichnisse und Dateien, die darauf liegen, nicht angesprochen werden. Das Mounten geschieht entweder manuell durch Eingabe des Kommandos mount oder aber automatisch beim Booten durch einen Eintrag in eine Konfigurationsdatei. Beides wird in Kapitel 7, »Linux«, gezeigt.
Eine weitere wichtige Eigenschaft der Dateien unter Unix sind die Benutzerrechte. Jede Datei gehört einem bestimmten Benutzer und einer bestimmten Gruppe (berechtigte Benutzer können diese Besitzverhältnisse ändern). Da ein Benutzer beliebig vielen Gruppen angehören kann, lassen sich die Rechte an bestimmten Dateien sehr effizient über das Gruppenzugriffsrecht ändern.
Der Verzeichniseintrag einer Datei enthält die Zugriffsrechte für den Besitzer, für die Gruppe und für alle anderen Benutzer. Die drei möglichen Zugriffsrechte sind Lesen (r für »read«), Schreiben (w für »write«) und Ausführen (x für »execute«). Ein typischer Verzeichniseintrag enthält beispielsweise die folgende Angabe von Zugriffsrechten:
-rwxr-xr-x
Die erste Stelle gibt den Dateityp an: – für eine gewöhnliche Datei, d für ein Verzeichnis oder l für einen Symlink. Die neun folgenden Informationen zeigen in Dreiergruppen die Zugriffsrechte an – drei Stellen für den Eigentümer, drei für die Gruppe und drei für alle anderen Benutzer. Ein Buchstabe steht dafür, dass ein Zugriffsrecht gewährt wird, ein Strich bedeutet, dass es nicht gewährt wird. Im vorliegenden Fall darf der Eigentümer die Datei lesen, schreiben (dazu gehören auch Löschen und Umbenennen) und ausführen. Die Gruppe und der Rest der Welt dürfen nur lesen und ausführen. Das Recht der Ausführung ist nur für Programme und für Verzeichnisse sinnvoll (Letztere lassen sich ansonsten nicht als Arbeitsverzeichnis auswählen).
Intern werden die Zugriffsrechte als dreistellige Oktalzahl gespeichert. Die erste Stelle enthält die Benutzerrechte des Eigentümers, die zweite die der Gruppe und die dritte die der anderen Benutzer. Der Wert jeder Stelle ist die Summe aus den gewährten Benutzerrechten: 4 steht für Lesen, 2 für Schreiben und 1 für Ausführen. Das Zugriffsrecht rwxr-xr-x lässt sich also als 0755 darstellen (die vorangestellte 0 steht für eine Oktalzahl). Eine einfache Textdatei könnte dagegen beispielsweise die Zugriffsrechte 0640 aufweisen, was rw-r----- entspricht – der Eigentümer darf die Datei lesen und schreiben, die Gruppe darf sie lesen, und alle anderen dürfen gar nichts.
Das virtuelle Windows-Dateisystem
Windows-Dateisysteme unterscheiden sich durch mehrere Merkmale von Unix-Dateisystemen. Insbesondere ist auffallend, dass es keine gemeinsame Wurzel für alle Dateisysteme gibt, sondern dass jeder Datenträger beziehungsweise jede Partition einen eigenen Verzeichnisbaum bildet. Die einzelnen Partitionen werden durch Laufwerksbuchstaben bezeichnet; die automatisch gewählte Reihenfolge gehorcht traditionell einigen seltsamen Regeln:
- A: ist das erste Diskettenlaufwerk, das es kaum noch gibt.
- B: ist das zweite Diskettenlaufwerk, das erst recht kein Mensch mehr einsetzt.
- C: ist die erste Partition auf der ersten physikalischen Platte (bei einem EIDE-System der Primary Master).
- D: ist die erste Partition auf der zweiten physikalischen Platte (dem Primary Slave). Falls das zweite EIDE-Gerät ein CD-ROM- oder DVD-Laufwerk ist, bekommt es einen höheren Buchstaben, und es geht zunächst mit den anderen Festplatten weiter.
- Die weiteren Buchstaben werden jeweils der ersten Partition der folgenden Platten zugewiesen, falls weitere vorhanden sind.
- Nun folgen Platte für Platte sämtliche restlichen Partitionen.
- Ganz am Schluss werden die CD-ROM- und DVD-Laufwerke in ihrer eigenen Anschlussreihenfolge berücksichtigt.
Windows-Versionen ab Vista bezeichnen dagegen automatisch die Partition, auf der sich das Betriebssystem befindet, als C:. Auch andere Abweichungen von der genannten Reihenfolge sind möglich, beispielsweise dann, wenn Sie nachträglich die Partitionierung ändern oder ein zusätzliches Laufwerk einbauen. Unter Windows 7 und 8 sowie früheren Systemen der Windows-NT-Familie können Sie die Zuordnung ohnehin mithilfe der Datenträgerverwaltung (Verwaltung · Computerverwaltung · Datenträgerverwaltung) ändern. Bei den Privatkunden-Versionen bis Windows Me war die freie Wahl der Laufwerksreihenfolge dagegen nur eingeschränkt möglich.
Pfade werden unter Windows so ähnlich angegeben wie bei Unix. Das Trennzeichen zwischen den Verzeichnisnamen sowie zwischen Verzeichnis und Datei ist allerdings der Backslash (\), der umgekehrte Schrägstrich. Die Wurzel innerhalb eines bestimmten Laufwerks ist ein einzelner Backslash, während ein vollständiger absoluter Pfad mit dem Laufwerksbuchstaben beginnt. Das jeweils übergeordnete Verzeichnis wird auch unter Windows durch zwei Punkte (..) angegeben.
Hier sehen Sie einen Auszug aus einem Windows-Verzeichnisbaum einer Festplatte mit dem Laufwerksbuchstaben D:
[D:]
|
+-- [dokumente]
|
+-- [fachinfo6]
| |
| +-- betriebssysteme.doc
|
+-- [sonstige]
Wenn Sie die Datei betriebssysteme.doc absolut ansprechen möchten, müssen Sie ihren vollständigen Pfad D:\dokumente\fachinfo6\betriebssysteme.doc angeben. Falls Sie sich dagegen bereits auf Laufwerk D: befinden, und zwar in einem beliebigen Verzeichnis, können Sie auch \dokumente\fachinfo6\betriebssysteme.doc schreiben. Ein relativer Zugriff aus dem Verzeichnis sonstige auf betriebssysteme.doc erfolgt über ..\fachinfo6\betriebssysteme.doc.
Das Konzept des Home-Verzeichnisses wird unter Windows bei Weitem nicht so konsequent verfolgt wie in Unix-Systemen. Zwar existiert unter Windows Vista auf der Systempartition ein Verzeichnis namens Users (in deutschen XP-Versionen heißt es dagegen Dokumente und Einstellungen), das für jeden Benutzer ein Unterverzeichnis enthält. In diesem Verzeichnis befindet sich beispielsweise das Unterverzeichnis Eigene Dateien, in dem standardmäßig die Dateien gespeichert werden sollten, die der Benutzer in Anwendungsprogrammen anlegt. Konfigurationsdaten werden dagegen nicht an dieser Stelle abgespeichert – die meisten befinden sich ohnehin nicht in Dateien, sondern in der Windows-Registry, die im nächsten Kapitel behandelt wird.
Zwar unterstützen nicht alle Windows-Dateisysteme die Verwaltung von Benutzerrechten, aber für jede Datei können vier verschiedene Attribute eingestellt werden: Das Attribut r steht für »read only«, also schreibgeschützt; s bezeichnet Systemdateien, die einen noch stärkeren Schutz genießen als schreibgeschützte. h oder »hidden« ist das Attribut für versteckte Dateien, die in der normalen Windows-Grundkonfiguration nicht angezeigt werden. a schließlich ist das Archiv-Attribut, das immer dann gesetzt wird, wenn die Datei seit dem letzten Systemstart geändert wurde. Archivieren müssen Sie also nur diejenigen Dateien, bei denen a gesetzt ist. Wie Sie die Attribute modifizieren können, erfahren Sie im folgenden Kapitel.
Dateinamen können unter Windows bis zu 255 Zeichen lang sein; zwischen Groß- und Kleinschreibung wird nicht unterschieden. Allerdings werden die Dateien genau mit der Groß- und Kleinbuchstabenkombination gespeichert, die Sie angegeben haben. Eine Reihe von Zeichen sind in Dateinamen nicht zulässig, vor allem :, \, /, ?, *, <, > und |. Alle diese Zeichen besitzen in Pfadangaben oder auf der Windows-Konsole besondere Bedeutungen.
Ein wesentlicher Bestandteil des Dateinamens ist unter Windows die Dateierweiterung oder -endung (Extension). Dieses Anhängsel, das durch einen Punkt vom restlichen Dateinamen getrennt wird und traditionell drei Buchstaben lang war, zeigt nämlich den Dateityp an: Wenn Sie unter Windows auf ein Datei-Icon doppelklicken, wird die Datei mit demjenigen Programm geöffnet, mit dem diese Endung verknüpft ist. Beispielsweise bezeichnet die Erweiterung .txt eine einfache Textdatei, .jpg ist eine Bilddatei im JPEG-Format, und .exe kennzeichnet ein ausführbares Programm.
Unglücklicherweise wird die Dateiendung in allen Windows-Versionen seit Windows 95 standardmäßig ausgeblendet, obwohl sie im Grunde ein normaler Bestandteil des Dateinamens ist. Sie können also nur noch an den mehr oder weniger aussagefähigen Datei-Icons erkennen, um welche Art von Datei es sich handelt. Dies lässt sich allerdings in den Ordneroptionen ändern und sollte eine der ersten Handlungen nach Inbetriebnahme einer neuen Windows-Installation sein.
Bei alten Windows-Versionen bis 3.11 waren Dateinamen auf acht Zeichen für den eigentlichen Namen und drei Zeichen für die Erweiterung begrenzt. Aus Gründen der Kompatibilität erzeugte Windows hinter den Kulissen noch lange Zeit für jeden Dateinamen, der länger ist, einen passenden Kurznamen. Dieser besteht aus folgenden Bestandteilen: den ersten fünf bis sechs Zeichen des eigentlichen Namens ohne Leerzeichen, einer Tilde und einer Nummer (um den Fall abzudecken, dass mehrere Dateien im gleichen Verzeichnis denselben Kurznamen erhalten würden) sowie der auf drei Zeichen gekürzten Erweiterung. Aus Der Name ist zu lang.doc würde nach diesem Schema DERNAM~1.DOC.
Ihr Kommentar
Wie hat Ihnen das <openbook> gefallen? Wir freuen uns immer über Ihre freundlichen und kritischen Rückmeldungen.

 Jetzt bestellen
Jetzt bestellen






