


15 XML
More matter, with less art.
– William Shakespeare
XML, die Extensible Markup Language (auf Deutsch: erweiterbare Auszeichnungssprache), ist kein bestimmtes Dokumentformat, sondern eine Metasprache zur Definition beliebiger Auszeichnungssprachen. Diese Sprachen können Textdokumente, Vektorgrafiken, multimediale Präsentationen, Datenbanken oder andere Arten von strukturierten Daten beschreiben. XML wurde vom World Wide Web Consortium (W3C) entworfen und standardisiert. Es handelt sich um eine schlanke, moderne und an Internetbedürfnisse angepasste Weiterentwicklung der klassischen Metasprache SGML (Standard Generalized Markup Language), die Ende der 60er-Jahre des vorigen Jahrhunderts erfunden und in den 80er-Jahren entscheidend weiterentwickelt wurde.
Die XML-Spezifikation selbst enthält nur wenige formale Regeln für den Aufbau von Dokumenten. Wenn Sie sich an diese (im weiteren Verlauf näher erläuterten) Regeln halten, erzeugen Sie ein wohlgeformtes XML-Dokument. Darüber hinaus besteht die Möglichkeit, Standards für XML-Dokumentformate zu definieren und Dokumente von diesen Standards abhängig zu machen. Dokumente, die auf solchen Formatdefinitionen basieren, sind nicht nur wohlgeformt, sondern auch gültig (oder valide). Die klassische, bereits in SGML bekannte Form für solche Dokumentklassen ist die Document Type Definition oder DTD. Moderne Alternativen, die zum einen leistungsfähiger sind und zum anderen selbst in reinem XML verfasst werden, sind XML Schema und RELAX NG (siehe http://www.relaxng.org).
Grundsätzlich bietet die Verwendung klartextbasierter Dokumentformate eine Reihe von Vorteilen gegenüber Binärdateien:
- Sämtliche Konfigurations- und Strukturinformationen sind für Menschen lesbar und können notfalls auch manuell geändert werden.
- Die Dokumente lassen sich auf jedem beliebigen Computersystem in einem einfachen Texteditor öffnen und eventuell bearbeiten. Der reine Textinhalt erschließt sich auch Anwendern, die die verwendeten Auszeichnungsbefehle nicht verstehen.
- Der Austausch von Dokumenten mit anderen Anwendungen, neuen Versionen einer Anwendung oder Programmiersprachen ist erheblich einfacher als bei Binärformaten.
Die interessanteste Frage ist eher, was XML gegenüber anderen textbasierten Auszeichnungssprachen auszeichnet. Zunächst haben fast alle textbasierten Formate außer XML spezielle Aufgaben: Beispielsweise dient LaTeX dem Erstellen von Vorlagen für den professionellen Satz; PostScript beschreibt dagegen fertig formatierte Ausgabeseiten für High-End-Drucker und -Belichter. Diese beiden Formate werden in Kapitel 16, »Weitere Datei- und Datenformate«, angesprochen. Des Weiteren besitzen UNIX-Serveranwendungen und viele andere Programme jeweils ein eigenes, ASCII-basiertes Konfigurationsdateiformat. In Kapitel 13, »Server für Webanwendungen«, werden zum Beispiel die Konfigurationsdateien des Webservers Apache erläutert.
XML ist dagegen eine universelle Sprache; es spielt keine Rolle, ob Sie Ihre Musik-CD-Sammlung, Ihre Doktorarbeit oder Ihre Geschäftsdaten in einem XML-Dokument speichern. Wichtig ist allerdings, zu verstehen, dass XML immer nur die Struktur und den Aufbau der Daten beschreibt. Das Layout der Druck- oder Webversion von Textinhalten muss durch eine externe Stil- oder Formatierungssprache beschrieben werden, beispielsweise durch das im weiteren Verlauf des Kapitels beschriebene XSLT. Auch die Aufbereitung und Darstellung von Datendokumenten ist nicht im XML-Format selbst festgelegt, sondern wird durch Programmierung oder durch ein spezielles Anwendungsprogramm durchgeführt.
Übrigens werden in der Praxis gar nicht so oft neue Dokumentformate für eigene Anwendungen entwickelt. Der überwiegende Anteil der Anwendungen von XML beruht auf dem Einsatz vorhandener XML-basierter Sprachen. Beispiele sind hier etwa die Webseiten-Auszeichnungssprache XHTML, das Vektorgrafikformat SVG (Scalable Vector Graphics) oder die beliebte Handbuch- und Dokumentationssprache DocBook. XHTML wird in Kapitel 17, »Webseitenerstellung mit (X)HTML und CSS«, näher erläutert.
Eine wichtige Frage wurde bisher noch nicht angesprochen: Wie werden XML-Dokumente editiert und abgespeichert? Darauf gibt es keine allgemeingültige Antwort. Prinzipiell handelt es sich bei XML-Dokumenten um Textdateien, Sie können sie also mit Ihrem bevorzugten Texteditor eingeben. Wichtig ist nur, dass der gewählte Editor den Zeichensatz unterstützt, den das XML-Dokument verwendet.
Neben den einfachen Texteditoren werden inzwischen unzählige spezielle XML-Editoren angeboten, sowohl Open-Source-Lösungen als auch kommerzielle Programme. Bekannte kommerzielle Editoren sind beispielsweise XMLSpy für Windows von der österreichischen Firma Altova (www.xmlspy.com) oder der Java-basierte Oxygen XML-Editor (www.oxygenxml.com). Zu den Open-Source-Lösungen gehört zum Beispiel der ebenfalls in Java geschriebene Editor Xerlin (www.xerlin.org).
Ein guter XML-Editor bietet neben dem direkten Bearbeiten der XML-Codes die Möglichkeit, XML-Dokumente in einer Baumansicht oder anderweitig visuell zu editieren. Außerdem sollten zusätzliche Formate wie DTDs, XML Schema, XSLT und so weiter unterstützt werden.
Abgesehen davon verwenden viele Anwendungsprogramme XML-basierte Datenformate, beispielsweise OpenOffice.org oder die neuesten Versionen der Microsoft-Office-Programme (bei beiden ist die Office-Arbeitsdatei ein ZIP-Archiv, in dem sich verschiedene XML-Dokumente und eventuell weitere Ressourcen wie Bilddateien befinden). Dennoch käme wohl kaum jemand auf die Idee, diese Dokumente von Hand mithilfe eines Text- oder XML-Editors zu bearbeiten.[Anm.: Ein unbestreitbarer Vorteil besteht aber natürlich darin, dass es relativ leicht ist, Programme zu schreiben, die diese Formate generieren.] Ebenso gibt es spezielle Editoren für besondere XML-Formate wie XHTML oder SVG. Letzteres lässt sich beispielsweise leicht aus Adobe Illustrator exportieren.
Gespeichert werden XML-Dokumente entweder als Datei mit der Endung .xml, wenn es sich um allgemeine XML-Dokumente handelt, oder mit einer speziellen Dateierweiterung, falls ein besonderes XML-Format verwendet wird. Zum Beispiel werden XHTML-Dokumente üblicherweise mit der Endung .html oder .htm gespeichert; SVG-Dateien besitzen dagegen die Erweiterung .svg.
Der für Webserver und E-Mail-Anwendungen wichtige MIME-Type allgemeiner XML-Dokumente ist text/xml, während spezielle Formate entweder einen ganz eigenen Typ wie text/html oder eine Kombination wie image/svg+xml bilden. Beachten Sie, dass ein SVG-Dokument zwar formal noch immer ein Textdokument ist, aber den Verwendungszweck eines Bildes erfüllt – deshalb der Haupttyp image.
15.1 Der Aufbau von XML-Dokumenten
Jedes XML-Dokument besteht aus einer Hierarchie ineinander verschachtelter Steueranweisungen, die als Elemente oder Tags bezeichnet werden, und kann zusätzlich einfachen Text enthalten. Die XML-Tags werden in spitze Klammern gesetzt, also zwischen ein <-Zeichen und ein >-Zeichen. Sie können ein oder mehrere Attribute in der Form attribut="wert" enthalten. Jedes Tag wird unter Angabe seiner Bezeichnung geöffnet (zum Beispiel <test>) und weiter unten im Dokument durch eine Wiederholung mit vorangestelltem Slash (/) wieder geschlossen (etwa </test>). Wahrscheinlich haben Sie eine solche Syntax schon einmal gesehen, wenn Sie sich den Quellcode von HTML-Dokumenten angeschaut haben, die ähnlich aufgebaut sind.
15.1.1 Die grundlegenden Bestandteile von XML-Dokumenten
Hier sehen Sie ein einfaches XML-Dokument, in dem eine Übersicht über diverse Comics geboten wird:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<comics>
<comic language="en-US">
<publisher>Marvel</publisher>
<series>The Amazing Spider-Man</series>
<format>Comic Book</format>
<issue>663</issue>
<title>The Return Of Anti-Venom</title>
<subtitle>Part One: The Ghost of Jean DeWolff</subtitle>
<authors>
<author role="Writer">Dan Slott</author>
<author role="Pencils">Giuseppe Camuncoli</author>
</authors>
<price currency="USD">3.99</price>
</comic>
<comic language="en-US">
<publisher>Marvel</publisher>
<series>Ultimate Spider-Man</series>
<format>Trade Paperback</format>
<issue original="1-13">1</issue>
<title>Ultimate Spider-Man</title>
<subtitle>Ultimate Collection</subtitle>
<authors>
<author role="Writer">Brian Michael Bendis</author>
<author role="Pencils">Mark Bagley</author>
</authors>
<price currency="USD">24.99</price>
</comic>
<comic language="en-US">
<publisher>DC Comics</publisher>
<series>Action Comics</series>
<format>Comic Book</format>
<issue>901</issue>
<title>Reign Of The Doomsdays</title>
<subtitle>Part 1</subtitle>
<authors>
<author role="Writer">Paul Cornell</author>
<author role="Artist">Kenneth Rocafort</author>
<author role="Artist">Jesus Merino</author>
</authors>
<price currency="USD">2.99</price>
</comic>
<comic language="en-US">
<publisher>Bongo Comics</publisher>
<series>Simpsons Comics</series>
<format>Comic Book</format>
<issue>178</issue>
<title>The Thingama-Bob From Outer Space</title>
<authors>
<author role="Writer">Eric Rogers</author>
<author role="Pencils">John Costanza</author>
</authors>
<price currency="USD">2.99</price>
</comic>
</comics>
Jedes XML-Dokument beginnt mit einer xml-Steueranweisung, die die verwendete XML-Version (1.0 oder – seit 2006 – auch 1.1) und den Zeichensatz des Dokuments angibt:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
Die hier verwendete Zeichencodierung utf-8 ist eine spezielle Schreibweise des Unicode-Zeichensatzes: Die ASCII-Zeichen 0 bis 127 benötigen nur 1 Byte, alle anderen Unicode-Zeichen dagegen 2 bis 4. Selbstverständlich können Sie auch andere Zeichensätze angeben, zum Beispiel iso-8859-1 für den USA/Westeuropa-Standardzeichensatz oder gb2312 für Chinesisch (VR China). Dazu muss der verwendete Zeichensatz allerdings von Ihrem Text- oder XML-Editor unterstützt werden.
Das Attribut standalone gibt an, ob sich das Dokument auf ein externes Formatdokument wie eine DTD oder ein XML Schema bezieht. Der Wert yes besagt, dass das Dokument selbstständig ist und nicht von einer solchen Standardisierung abhängt. Ein solches Dokument muss wohlgeformt sein, aber es ist nicht valide, da es keine Spezifikation gibt, gegen die seine Gültigkeit geprüft werden könnte.
Steueranweisungen (auch PI, Processing Instructions) können in XML-Dokumenten an beliebiger Stelle vorkommen. Es handelt sich um Anweisungen für interpretierende Geräte oder Programme, die mit dem Dokument selbst nichts zu tun haben.
XML-Elemente
Es ist wichtig, dass genau ein Tag, das Wurzelelement, das gesamte Dokument umschließt. Das Wurzelelement des vorliegenden Dokuments sieht folgendermaßen aus:
<comics>
<!-- umschlossener Inhalt -->
</comics>
Innerhalb des Wurzelelements sind weitere Elemente mit ihren Unterelementen und Textinhalten verschachtelt. Das Wichtigste ist dabei, dass Sie auf die korrekte Reihenfolge bei der Verschachtelung achten müssen. Eine Schreibweise wie die folgende ist nicht gestattet:
<author><name>Bendis</author></name>
Richtig muss es folgendermaßen lauten:
<author><name>Bendis</name></author>
Die hierarchische Gliederung von XML-Dokumenten ergibt eine Art Baumdiagramm. Das Wurzelelement bildet logischerweise die Wurzel, die verschachtelten Elemente sind die Äste und Zweige und die Textinhalte die Blätter. Abbildung 15.1 zeigt einen Ausschnitt des Comic-Dokuments in Form eines solchen Diagramms.
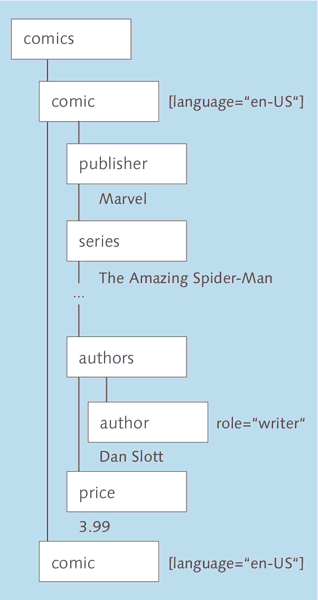
Abbildung 15.1 Darstellung eines XML-Dokuments in Form einer Baumstruktur
Die Namen von Tags und den im weiteren Verlauf besprochenen Attributen dürfen aus Buchstaben und Ziffern sowie aus den folgenden Sonderzeichen bestehen: _ (Unterstrich), - (Bindestrich) und . (Punkt). Das erste Zeichen darf keine Ziffer sein. Es wird zwischen Groß- und Kleinschreibung unterschieden.
Jedes XML-Tag, das geöffnet wurde, muss auch wieder geschlossen werden. Erst das öffnende und das schließende Tag zusammen ergeben das eigentliche Element. Geschlossen wird ein Tag durch die Wiederholung seines Namens mit vorangestelltem Slash (/). In der Regel steht zwischen den beiden Tags Inhalt, der aus tiefer verschachtelten Tags oder aus einfachem Text bestehen kann. Mitunter kommt es jedoch vor, dass ein Element leer ist, also keinen weiteren Inhalt enthält.
Zum Beispiel könnte die Comic-Liste für jeden Comic ein zusätzliches Element enthalten, das auf den Dateinamen und den MIME-Type einer Abbildung des Covers verweist. Für diese Angaben würden sich Attribute (siehe nächster Abschnitt) besonders gut eignen:
...
<title>The Thingama-Bob From Outer Space</title>
<cover file="simpsons_178.png" type="image/png">
</cover>
...
Da alle erforderlichen Informationen über das Cover-Bild bereits in den Attributen stehen, benötigt das Element cover keinen verschachtelten Inhalt. Falls Sie bereits Kenntnisse in HTML haben, könnten Ihnen die dort verwendeten »Einfach-Tags« wie der Zeilenumbruch <br> vertraut sein. In XML ist eine solche Ausnahme nicht zulässig, die Schreibweise stammt noch aus SGML. Als »Entschädigung« bietet XML allerdings eine kurz gefasste Schreibweise für leere Elemente an. Das cover-Element könnten Sie entsprechend dieser Syntax auch folgendermaßen schreiben:
Der Slash am Ende des Tags ersetzt also das vollständige, schließende Tag. Das Leerzeichen vor dem End-Slash ist nach der eigentlichen XML-Syntax nicht erforderlich. Allerdings ist es nützlich, um kompatiblen Code für sehr alte Browser abzuliefern, die nur klassisches HTML, aber kein XHTML verstehen. Der zuvor erwähnte Zeilenumbruch wird in der voll kompatiblen Fassung also so geschrieben:
<br />
Alte Browser ignorieren den Slash einfach, während XML-Parser kein Problem mit dem Leerzeichen haben. Falls Sie dagegen einfach <br/> schreiben, versteht ein älterer Browser dies möglicherweise nicht, weil er es für ein unbekanntes Tag hält.
Genaueres über klassisches HTML im Unterschied zu XHTML und dem neuen HTML5 erfahren Sie in Kapitel 17, »Webseitenerstellung mit (X)HTML und CSS«.
Attribute
Das Element comic enthält jeweils ein Attribut namens language und gegebenenfalls isbn. Attribute stehen nur beim öffnenden Tag und werden beim schließenden niemals wiederholt. Die Form ist stets attributname="attributwert" oder attributname= 'attributwert'. Die doppelten oder einfachen Anführungszeichen sind zwingend erforderlich. Zwischen dem Attributnamen, dem Gleichheitszeichen und dem öffnenden Anführungszeichen ist kein Abstand erlaubt, während mehrere Attribute durch Whitespace voneinander getrennt werden, genau wie Tag-Name und Attribut.
Allgemein werden Attribute häufig verwendet, um Ordnungskriterien oder Metainformationen für Elemente anzugeben. Allerdings ergäbe sich kein Unterschied im Informationsgehalt des Dokuments, wenn Sie statt
<comic language="en-US">
...
</comic>
die folgende Schreibweise wählen würden:
<comic>
<language>en-US</language>
...
</comic>
Beachten Sie jedoch, dass Attribute immer nur für Informationen geeignet sind, die nur einmal pro Element vorkommen. Es ist nämlich nicht zulässig, zwei Attribute gleichen Namens in ein und demselben Tag zu verwenden. Außerdem ist ein Attribut naturgemäß nicht für mehrgliedrige Angaben geeignet, die eigentlich verschachtelt werden müssen.
Das folgende Beispiel zeigt einen extrem schlechten Stil bei der Verwendung von Attributen, da es vor allem die erste Regel missachtet:
<comic language="en-US" author1="Brian Michael Bendis" author2="Mark Bagley">
...
</comic>
Was machen Sie aber, wenn ein Comic zehn Autoren hat (bei Sammelbänden ist das keine Seltenheit)?
Noch übler ist die folgende Schreibweise, die beide Regeln ignoriert:
<comic language="en-US" author-lastname1="Bendis"
author-firstname1="Brian Michael" author-lastname2="Bagley"
author-firstname2="Mark">
...
</comic>
Diese beiden schlechten Beispiele sollten Sie so schnell wie möglich wieder vergessen; sie sind zwar formal zulässig, stilistisch aber vollkommen indiskutabel.
Entity-Referenzen
In Abschnitt 15.4, »Grundlagen der XML-Programmierung«, kommt ein XML-Dokument zum Einsatz, das verschiedene XML-Fachbücher beschreibt. Eines der Bücher hat die Verlagsangabe O'Reilly – ' ersetzt in einem XML-Dokument den Apostroph.
Einige Zeichen sind in XML-Dokumenten nicht zulässig, sondern müssen durch spezielle Escape-Sequenzen ersetzt werden, die als Entity-Referenzen bezeichnet werden. Eine Entity-Referenz beginnt mit einem &-Zeichen, darauf folgt ein spezieller Code und am Ende ein Semikolon. Tabelle 15.1 zeigt die fünf Zeichen, die nicht gestattet sind, und die passenden Entity-Referenzen.
| Zeichen | Entity-Referenz | Bedeutung |
|
< |
< |
less than (kleiner als) |
|
> |
> |
greater than (größer als) |
|
& |
& |
Ampersand (»and per se and«) |
|
' |
' |
Apostroph |
|
" |
" |
quotation mark (Anführungszeichen) |
Alle diese Zeichen haben im XML-Code eine spezielle Bedeutung: < und > umschließen die Tags. Die Werte von Attributen stehen in Anführungszeichen oder wahlweise in einfachen Anführungszeichen (Apostrophen). Das &-Zeichen schließlich leitet eben die Entity-Referenzen ein.
Neben diesen vorgefertigten Entity-Referenzen können Sie in XML auch beliebige Unicode-Zeichen numerisch angeben. Die Syntax ist entweder &#Dezimalcode; oder &#xHexadezimalcode;. Beispielsweise erzeugen Sie ein »Registered Trademark«-Zeichen ® durch die Zeichenfolge ® (dezimal) oder ® (hexadezimal).
Schließlich können Sie eigene Entitys definieren und in Ihren Dokumenten Referenzen darauf verwenden. Dies ermöglicht Ihnen den schnellen Zugriff auf häufig benötigte Sonderzeichen oder sogar XML-Codeblöcke. Die Definition von Entitys wird innerhalb von DTDs durchgeführt, die in Abschnitt 15.2, »DTDs und XML Schema«, behandelt werden.
CDATA-Abschnitte
Der normale Text in XML-Dokumenten besteht aus sogenannten PCDATA-Abschnitten. PCDATA steht für »parsed character data«. Dies bedeutet, dass einige Sonderzeichen innerhalb des Textes gemäß ihrer speziellen XML-Bedeutung behandelt werden – es sei denn, Sie verwenden die im vorigen Abschnitt vorgestellten Entity-Referenzen.
In einigen Fällen können Entity-Referenzen sehr störend sein. Stellen Sie sich zum Beispiel eine XML-Version des vorliegenden Kapitels vor. Diese müsste in normalen Textabschnitten die Entity-Referenzen verwenden.
Der folgende Code ist die XML-Entsprechung eines Ausschnitts aus dem vorigen Abschnitt:
<para>
Das <code>cover</code>-Element könnten Sie entsprechend dieser
Syntax auch folgendermaßen schreiben:
</para>
<codeblock>
<cover file="simpsons_178.png"
type="image/png" />
</codeblock>
<para>
Der Slash am Ende des Tags ersetzt also das vollständige
schließende Tag.
</para>
Das XML-Codebeispiel zwischen den Tags <codeblock> und </codeblock> ist durch die Häufung von Entity-Referenzen absolut unleserlich. Um solche Probleme zu vermeiden, haben sich die XML-Entwickler ein spezielles Format für solche Textblöcke ausgedacht, die sogenannten CDATA-Abschnitte. Diese Abkürzung bedeutet »character data«. Innerhalb dieser speziellen Bereiche sind alle Sonderzeichen erlaubt und werden nicht als XML interpretiert.
Ein CDATA-Abschnitt wird durch die Sequenz <![CDATA[ eingeleitet und durch ]]> abgeschlossen. Mithilfe eines CDATA-Abschnitts wird das vorige Beispiel sofort viel lesbarer:
<para>
Das <code>cover</code>-Element könnten Sie entsprechend dieser
Syntax auch folgendermaßen schreiben:
</para>
<codeblock>
<![CDATA[
<cover file="simpsons_178.png"
type="image/png" />
]]>
</codeblock>
<para>
Der Slash am Ende des Tags ersetzt also das vollständige
schließende Tag.
</para>
Es versteht sich von selbst, dass die Zeichenfolge ]]> innerhalb eines CDATA-Blocks unzulässig ist – schließlich beendet sie ebendiesen Block. Genau deshalb wurde eine so unwahrscheinliche Zeichensequenz gewählt.
Kommentare
Zu guter Letzt können XML-Dokumente auch noch Kommentare enthalten. Ein Kommentar wird naturgemäß ignoriert;[Anm.: Die im letzten Abschnitt dieses Kapitels vorgestellten XML-Parser zur Programmierung XML-basierter Anwendungen können allerdings bei Bedarf auf Kommentare reagieren.] er dient Ihrer eigenen Übersicht im Dokument oder kann zusätzliche Erläuterungen enthalten. Ein Kommentar wird durch die Zeichenfolge <!-- eingeleitet und endet mit -->. Er kann sich über beliebig viele Zeilen erstrecken. In den Beispielen zuvor wurden Kommentare bereits als Auslassungsmarkierung oder für Erläuterungen verwendet.
Hier ein Beispiel für einen XML-Block mit einem Kommentar:
<authors>
<author role="Writer">Brian Michael Bendis</author>
<author role="Pencils">Mark Bagley</author>
<!-- An dieser Stelle fehlen Inks, Colors und Letters -->
</authors>
Wenn Sie Kommentare nutzen, um einen unerwünschten Bereich Ihres XML-Dokuments vorübergehend zu deaktivieren, müssen Sie darauf achten, dass der Block selbst keine Kommentare enthält, denn beim ersten Auftreten der Sequenz --> ist alles Weitere kein Kommentar mehr, und das nächste --> gilt wegen des alleinstehenden, nicht als Entity-Sequenz geschriebenen > sogar als Fehler.
15.1.2 Wohlgeformtheit
Jedes XML-Dokument muss eine Reihe formaler Regeln erfüllen, um wohlgeformt zu sein. XML-Dateien, die diesen Regeln nicht genügen, werden von XML-Parsern in Anwendungen und Programmiersprachen nicht verarbeitet, sondern erzeugen Fehlermeldungen. In diesem Abschnitt werden die Regeln für die Wohlgeformtheit noch einmal explizit erläutert. Zwar wurden sie bereits am Rande erwähnt, sind aber wichtig genug, um genauer erklärt zu werden.
Hier sehen Sie zunächst eine kurze Liste aller Regeln für die Wohlgeformtheit:
- Ein XML-Dokument benötigt genau ein Wurzelelement: Ein bestimmtes Element muss alle anderen Elemente und Textinhalte umschließen.
- Alle Elemente müssen korrekt ineinander verschachtelt werden; das zuletzt geöffnete Element wird als Erstes wieder geschlossen.
- Jedes Element besteht aus einem öffnenden und einem schließenden Tag; »Einfach-Tags« wie in klassischem HTML gibt es nicht. Für leere Tags existiert die spezielle Kurzfassung mit dem End-Slash.
- Attribute haben die Form name="wert". Der Wert muss stets in Anführungszeichen stehen.
- Die Namen von Elementen und Attributen dürfen nur Buchstaben, Ziffern, Unterstriche, Bindestriche und Punkte enthalten. Es wird zwischen Groß- und Kleinschreibung unterschieden. Das erste Zeichen darf keine Ziffer sein.
- Bestimmte Zeichen sind in XML-Dokumenten nicht zulässig: <, >, &, " und ' müssen durch die Entity-Referenzen <, >, &, " und ' ersetzt werden. Die Definition weiterer Entity-Referenzen ist zulässig, aber sie dürfen nicht undefiniert verwendet werden.
- CDATA-Blöcke ermöglichen die beliebige Verwendung der Sonderzeichen, die normalerweise durch Entity-Referenzen ersetzt werden müssen. Ein CDATA-Abschnitt steht zwischen <![CDATA[ und ]]>.
Die meisten dieser Regeln wurden eingangs bereits ausführlich genug erläutert. Im Folgenden wird allerdings noch einmal die Bedeutung des Wurzelelements und der korrekten Verschachtelung von Tags hervorgehoben.
Wurzelelemente
Die Forderung nach einem Wurzelelement bedeutet, dass Code wie der folgende kein vollständiges XML-Dokument bildet:
<comic>
<series>Fantastic Four</series>
</comic>
<comic>
<series>Detective Comics</series>
</comics>
Dies ist bestenfalls ein Dokumentfragment. Manche XML-fähigen Anwendungen sind in der Lage, mit solchen Fragmenten umzugehen. Sie dürfen sich allerdings niemals darauf verlassen. Korrekt wäre dagegen folgende Fassung:
<comics>
<comic>
<series>Fantastic Four</series>
</comic>
<comic>
<series>Detective Comics</series>
</comic>
</comics>
Das Element comics ist das Wurzelelement des gesamten Dokuments: Die Tags <comics> und </comics> umschließen alle anderen Inhalte.
Bei vielen vordefinierten XML-basierten Dokumentformaten ist das Wurzelelement ein Hinweis auf das Format selbst. Beispielsweise lautet das Wurzelelement eines XHTML-Dokuments html. Der gesamte Inhalt von HTML-Dokumenten wird also von den Tags <html> und </html> umschlossen.
Korrekte Verschachtelung
Wie bereits erwähnt, muss die korrekte Verschachtelungsreihenfolge von XML-Elementen beachtet werden. Tags werden von außen nach innen geöffnet und in umgekehrter Reihenfolge wieder geschlossen. Das zuletzt geöffnete Tag wird demnach zuerst geschlossen.
Diese Regel ist im Grunde leicht zu merken und einzuhalten. Vielleicht verwirrt es Sie aber in dem Fall, dass zwei Tags unmittelbar hintereinander geöffnet werden, die Sie später auch wieder gleichzeitig schließen möchten.
Stellen Sie sich beispielsweise vor, Sie hätten für die Formatierung eines Textdokuments zwei Elemente namens fett und kursiv definiert und wollten nun einige Wörter fett und kursiv darstellen. In diesem Fall könnte es leicht passieren, dass Sie denken: Diese Wörter sollen fett und kursiv sein. Wenig später denken Sie sich: Dieses Wort soll allerdings nicht mehr fett und nicht mehr kursiv sein. Dieser Sprachgebrauch würde die folgende Formulierung in XML nahelegen:
Dieser Text ist <fett><kursiv>fett und kursiv</fett></kursiv>
und dieser nicht mehr.
Allerdings ist dieses Konstrukt absolut verboten. Die richtige Syntax lautet natürlich folgendermaßen:
Dieser Text ist <fett><kursiv>fett und kursiv</kursiv></fett>
und dieser nicht mehr.
Gute XML- oder HTML-Editoren weisen im Übrigen schon während der Eingabe darauf hin, dass Sie eine falsche Verschachtelung verwendet haben, oder sie erstellen das schließende Tag automatisch, sobald Sie das öffnende hingeschrieben haben.
Ihr Kommentar
Wie hat Ihnen das <openbook> gefallen? Wir freuen uns immer über Ihre freundlichen und kritischen Rückmeldungen.

 Jetzt bestellen
Jetzt bestellen






