


5.3 Prozesse, Tasks und Threads
Nachdem wir nun die Grundlagen geklärt haben, wollen wir auf die interessanten Einzelheiten zu sprechen kommen. Wir werden die Begriffe Prozess, Thread und Task sowie deren »Lebenszyklen« im System analysieren und dabei auch einen kurzen Blick auf das Scheduling werfen. Ebenfalls interessant wird ein Abschnitt über die Implementierung dieser Strukturen im Kernel sein.
Was in diesem Kapitel zum Kernel über Prozesse fehlt – die Administration und die Userspace-Sicht – können Sie in einem eigenen Kapitel nachlesen. Im aktuellen Kernel-Kontext interessieren uns eher das Wesen und die Funktion als die konkrete Bedienung, die eigentlich auch nichts mehr mit dem Kernel zu tun hat – sie findet ja im Userspace [Fn. Wörtlich übersetzt heißt das Wort »Raum des Benutzers«, meint also den eingeschränkten Ring 3, in dem alle Programme ausgeführt werden.] statt. [Fn. Wenn Sie jetzt den Einspruch wagen, dass die zur Administration der Prozesse benutzten Programme nun auch wieder über Syscalls auf den Kernel zugreifen und so ihre Aktionen erst ausführen können, haben Sie verstanden, worum es geht.]
5.3.1 Definitionen
Beginnen wir also mit den Definitionen. Anfangs haben wir bereits die aus der Erwartung der Benutzer resultierende Notwendigkeit des Multitasking-Betriebs erläutert. Der Benutzer möchte nun einmal mehrere Programme gleichzeitig ausführen können, die Zeiten von MS-DOS und des Singletaskings sind schließlich vorbei. Die Programme selbst liegen dabei als Dateien irgendwo auf der Festplatte.
Prozess
Programm samt Laufzeitdaten
Wird ein Programm nun ausgeführt, spricht man von einem Prozess. Dabei hält das Betriebssystem natürlich noch einen ganzen Kontext weiterer Daten vor: die ID des ausführenden Benutzers, bereits verbrauchte Rechenzeit, alle geöffneten Dateien – alles, was für die Ausführung wichtig ist.
Ein Prozess ist ein Programm in Ausführung.
Besonders hervorzuheben ist, dass jeder Prozess seinen eigenen virtuellen Adressraum besitzt. Wie dieser Speicherbereich genau organisiert ist, werden wir später noch im Detail klären. Im Moment ist jedoch wichtig zu wissen, dass im virtuellen Speicher nicht nur die Variablen des Programms, sondern auch der Programmcode selbst sowie der Stack enthalten sind.
Der Stack
Funktionsaufrufe abbilden
Der Stack ist eine besondere Datenstruktur, über die man Funktionsaufrufe besonders gut abbilden kann. Sie bietet folgende Operationen:
- push
Mit dieser Operation kann man ein neues Element auf den Stack legen. Auf diese Weise erweitert man die Datenstruktur um ein Element, das gleichzeitig zum aktuellen Element wird. - top
Mit dieser Operation kann man auf das oberste beziehungsweise aktuelle Element zugreifen und es auslesen. Wendet man sie an, so bekommt man das letzte per push auf den Stack geschobene Element geliefert. - pop
Mit dieser Operation kann man schließlich das oberste Element vom Stack löschen. Beim nächsten Aufruf von top würde man also das Element unter dem von pop gelöschten Element geliefert bekommen.
Die einzelnen Funktionen und ihre Auswirkungen auf den Stack sind in der folgenden Abbildung veranschaulicht – push und pop bewirken jeweils eine Veränderung der Datenstruktur, während top auf der aktuellen Datenstruktur operiert und das oberste Element zurückgibt:
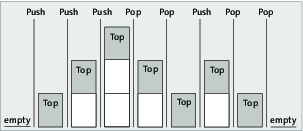
Abbildung 5.5 Das Prinzip eines Stacks
Um zu veranschaulichen, wieso diese Datenstruktur so gut das Verhalten von Funktionsaufrufen abbilden kann, betrachten wir das folgende kleine C-Beispiel:
Listing 5.7 Ein modifiziertes »Hello World!«-Programm
#include <stdio.h>
void funktion1()
{
printf("Hello World!\n");
return;
}
int main()
{
funktion1();
return 0;
}
Verschachtelte Aufrufe
In diesem Beispiel wird die Funktion funktion1() aus dem Hauptprogramm heraus aufgerufen. Diese Funktion wiederum ruft die Funktion printf() mit einem Text als Argument auf. Der Stack für die Funktionsaufrufe verändert sich während der Ausführung wie folgt:
- Start des Programms
Beim Start des Programms ist der Stack zwar vom Betriebssystem initialisiert, aber im Prinzip noch leer. [Fn. Das ist zwar nicht ganz richtig, aber für uns erst einmal uninteressant. ] - Aufruf von funktion1()
An dieser Stelle wird der Stack benutzt, um sich zu merken, wo es nach der Ausführung von funktion1() weitergehen soll. Im Wesentlichen wird also das Befehlsregister auf den Stack geschrieben – und zwar mit der Adresse des nächsten Befehls nach dem Aufruf der Funktion: von return. Es werden in der Realität auch noch andere Werte auf den Stack geschrieben, aber diese sind hier für uns uninteressant. Schließlich wird der Befehlszeiger auf den Anfang von funktion1() gesetzt, damit die Funktion ablaufen kann. - In der Funktion funktion1()
Hier wird sofort eine weitere Funktion aufgerufen: printf() aus der C-Bibliothek mit dem Argument »Hello World!«. Auch hier wird wieder die Adresse des nächsten Befehls auf den Stack geschrieben. Außerdem wird auch das Argument für die Funktion, also eben unser Text, auf dem Stack abgelegt. [Fn. Es gibt auch Rechnerarchitekturen, bei denen man die Parameterübergabe anders regelt. Dass auf einem MIPS-System die Parameter über die Prozessorregister übergeben werden, haben Sie in unserem Syscall-Beispiel direkt in Assembler schon gesehen.] - Die Funktion printf()
Die Funktion kann jetzt das Argument vom Stack lesen und somit unseren Text schreiben. Danach wird der vor dem Aufruf von printf() auf den Stack gelegte Befehlszeiger ausgelesen und das Befehlsregister mit diesem Wert gefüllt. So kann schließlich funktion1() ganz normal mit dem nächsten Befehl nach dem Aufruf von printf() weitermachen. Dies ist nun schon ein Rücksprungbefehl, der das Ende der Funktion anzeigt. - Das Ende
Wir kehren nun ins Hauptprogramm zurück und verfahren dabei analog wie beim Rücksprung von printf() zu funktion1(). Wie man sieht, eignet sich der Stack also prächtig für Funktionsaufrufe: Schließlich wollen wir nach dem Ende einer Funktion in die aufrufende Funktion zurückkehren – anderen interessieren uns nicht. Mit dem Rücksprung nach main() ist unser Programm abgeschlossen und wird vom Betriebssystem beendet.
Es liegen noch mehr Daten auf dem Stack als nur der Befehlszeiger oder die Funktionsargumente – mit diesen Daten werden wir uns später noch auseinandersetzen.
Thread
Kommen wir also zur nächsten Definition. Im letzten Abschnitt haben wir einen Prozess als ein Programm in Ausführung definiert. Jedoch ist klar, dass die eigentliche Ausführung nur von den folgenden Daten abhängt:
- dem aktuellen Befehlsregister
- dem Stack
- dem Inhalt der Register des Prozessors
Ausführungsfaden
Ein Prozess besteht nun vereinfacht gesagt aus dem eigenen Speicherbereich, dem Kontext (wie zum Beispiel den geöffneten Dateien) und genau einem solchen Ausführungsfaden, einem sogenannten Thread.
Ein Thread ist ein Ausführungsfaden, der aus einem aktuellen Befehlszeiger, einem eigenen Stack und dem Inhalt der Prozessorregister besteht.
Ein auszuführendes Programm kann nun theoretisch auch mehrere solcher Threads besitzen. Das bedeutet, dass diese Ausführungsfäden quasiparallel im selben Adressraum laufen. Diese Eigenschaft ermöglicht ein schnelles Umschalten zwischen verschiedenen Threads einer Applikation. Außerdem erleichtert die Möglichkeit zur parallelen Programmierung einer Applikation die Arbeit des Programmierers teilweise deutlich.
User- oder Kernelspace?
Threads müssen dabei nicht notwendigerweise im Kernel implementiert sein: Es gibt nämlich auch sogenannte Userlevel-Threads. Für das Betriebssystem verhält sich die Applikation wie ein normaler Prozess mit einem Ausführungsfaden. Im Programm selbst sorgt jetzt jedoch eine besondere Bibliothek dafür, dass eigens angelegte Stacks richtig verwaltet und auch die Threads regelmäßig umgeschaltet werden, damit die parallele Ausführung gewährleistet ist.
Außerdem gibt es neben den dem Kernel bekannten KLTs (Kernellevel-Threads) und den eben vorgestellten PULTs (Puren Userlevel-Threads) auch noch sogenannte Kernelmode-Threads. Diese Threads sind nun Threads des Kernels und laufen komplett im namensgebenden Kernelmode.
Normalerweise wird der Kernel eigentlich nur bei zu bearbeitenden Syscalls und Interrupts aktiv. Es gibt aber auch Arbeiten, die unabhängig von diesen Zeitpunkten, vielleicht sogar periodisch ausgeführt werden müssen. Solche typischen Aufgaben sind zum Beispiel das regelmäßige Aufräumen des Hauptspeichers oder das Auslagern von lange nicht mehr benutzten Speicherseiten auf die Festplatte, wenn der Hauptspeicher einmal besonders stark ausgelastet ist.
Task
Prozess + x Threads
Ein Task ist eigentlich nichts anderes als ein Prozess mit mehreren Threads. Zur besseren Klarheit wird teilweise auch die folgende Unterscheidung getroffen: Ein Prozess hat einen Ausführungsfaden, ein Task hat mehrere. Somit ist ein Prozess ein Spezialfall eines Tasks. Aus diesem Grund gibt es auch keine Unterschiede bei der Realisierung beider Begriffe im System.
Unter Unix spricht man trotzdem meistens von Prozessen, da hier das Konzept der Threads im Vergleich zur langen Geschichte des Betriebssystems noch relativ neu ist. So hat zum Beispiel Linux erst seit Mitte der 2.4er-Reihe eine akzeptable Thread- Unterstützung. Vorher war die Erstellung eines neuen Threads fast langsamer als die eines neuen Prozesses, was dem ganzen Konzept natürlich widerspricht. Aber mittlerweile ist die Thread-Unterstützung richtig gut, und somit ist auch eines der letzten Mankos von Linux beseitigt.
Identifikationsnummern
Damit das Betriebssystem die einzelnen Prozesse, Threads und Tasks unterscheiden kann, wird allen Prozessen beziehungsweise Tasks eine Prozess-ID (PID) zugewiesen. Diese PIDs sind auf jeden Fall eindeutig im System.
Threads haben entsprechend eine Thread-ID (TID). Ob TIDs nun aber im System oder nur innerhalb eines Prozesses eindeutig sind, ist eine Frage der Thread-Bi- bliothek. Ist diese im Kernel implementiert, ist es sehr wahrscheinlich, dass die IDs der Threads mit den IDs der Prozesse im System eindeutig sind. Schließlich gilt es für das Betriebssystem herauszufinden, welcher Prozess oder Thread als Nächstes laufen soll. Dazu ist natürlich ein eindeutiges Unterscheidungsmerkmal wichtig. Allerdings könnte auch das Tupel (Prozess-ID, Thread-ID) für eine solche eindeutige Identifizierung herangezogen werden, falls die TID nur für jeden Prozess eindeutig ist.
Ist der Thread-Support nur im Userspace über eine Bibliothek implementiert, so ist eine eindeutige Identifizierung für den Kernel unnötig – er hat mit der Umschaltung der Threads nichts zu tun. So werden die TIDs nur innerhalb des betreffenden Tasks eindeutig sein.
Mehr zu PIDs erfahren Sie in Kapitel 26, »Prozesse und IPC«.
5.3.2 Lebenszyklen eines Prozesses
Der nächste wichtige Punkt – die Lebenszyklen eines Prozesses – betrifft die Tasks; Threads spielen in diesem Kontext keine Rolle.
Unterschiedliche Zustände
Ein Prozess hat verschiedene Lebensstadien. Das wird schon deutlich, wenn man sich vor Augen führt, dass er erstellt, initialisiert, verarbeitet und beendet werden muss. Außerdem gibt es noch den Fall, dass ein Prozess blockiert ist – wenn er zum Beispiel auf eine (Tastatur-)Eingabe des Benutzers wartet, dieser sich aber Zeit lässt.
Prozesserstellung
Zuerst wollen wir die Geburt eines neuen Prozesses betrachten. Dabei interessieren uns zunächst die
Zeitpunkte, an denen theoretisch neue Prozesse erstellt werden könnten:
- Systemstart
- Anfrage eines bereits laufenden Prozesses zur Erstellung eines neuen Prozesses
- Anfrage eines Users zur Erstellung eines neuen Prozesses
- Starten eines Hintergrundprozesses (Batch-Job)
Der »Urprozess« init
Sieht man sich diese Liste näher an, so fällt auf, dass die letzten drei Punkte eigentlich zusammengefasst werden können: Wenn man einen neuen Prozess als Kopie eines bereits bestehenden Prozesses erstellt, braucht man sich nur noch beim Systemstart um einen Urprozess zu kümmern. Von diesem werden schließlich alle anderen Prozesse kopiert, indem ein Prozess selbst sagt, dass er kopiert werden möchte. Da die Benutzer das System ausschließlich über Programme bedienen, können die entsprechenden Prozesse auch selbst die Erstellung eines neuen Prozesses veranlassen – Punkt 3 wäre damit also auch abgedeckt. Bleiben noch die ominösen Hintergrundjobs: Werden diese durch einen entsprechenden Dienst auf dem System gestartet, so reicht auch für diese Arbeit das einfache Kopieren eines Prozesses aus.
fork() und exec*()
Eine solche Idee impliziert aber auch die strikte Trennung zwischen dem Starten eines Prozesses und dem Starten eines Programms. So gibt es denn auch zwei Syscalls: fork() kopiert einen Prozess, so dass das alte Programm in zwei Prozessen ausgeführt wird, und exec*() ersetzt in einem laufenden Prozess das alte Programm durch ein neues. Offensichtlich kann man die häufige Aufgabe des Startens eines neuen Programms in einem eigenen Prozess dadurch erreichen, dass erst ein Prozess kopiert und dann in der Kopie das neue Programm gestartet wird.
Beim fork()-Syscall muss man also nach dem Aufruf unterscheiden können, ob man sich im alten oder im neuen Prozess befindet. Eine einfache Möglichkeit dazu ist der Rückgabewert des Syscalls: Dem Kind wird 0 als Ergebnis des Aufrufs zurückgegeben, dem Elternprozess dagegen die ID des Kindes:
Listing 5.8 Ein fork-Beispiel
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
if( fork() == 0 )
{
// Hier ist der Kindprozess
printf("Ich bin der Kindprozess!\n");
}
else
{
// Hier ist der Elternprozess
printf("Ich bin der Elternprozess!\n");
}
return 0;
}
Im obigen Beispiel wurde dabei die Prozess-ID (PID), die der fork()-Aufruf dem erzeugenden Prozess übergibt, ignoriert. Wir haben diese Rückgabe nur auf die Null überprüft, die den Kindprozess anzeigt. Würde den erzeugenden Prozess anders als in diesem Beispiel doch die PID des Kindes interessieren, so würde man den Rückgabewert von fork() einer Variablen zuweisen, um diese schließlich entsprechend auszuwerten.
Listing 5.9 Das Starten eines neuen Programms in einem eigenen Prozess
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
if( fork() == 0 )
{
execl( "/bin/ls", "ls", NULL );
}
return 0;
}
Ein neues Programm starten
In diesem Beispiel haben wir wie beschrieben ein neues Programm gestartet: Zuerst wird ein neuer Prozess erzeugt, in dem dann das neue Programm ausgeführt wird. Beim Starten eines neuen Programms wird fast der gesamte Kontext des alten Prozesses ausgetauscht – am wichtigsten ist dabei der virtuelle Speicher.
Das neue Programm erhält nämlich einen neuen Adressraum ohne die Daten des erzeugenden Prozesses. Dies erfordert auf den ersten Blick unnötig doppelte Arbeit: Beim fork() wird der Adressraum erst kopiert und eventuell sofort wieder verworfen und durch einen neuen, leeren Speicherbereich ersetzt.
Dieses Dilemma umgeht man durch ein einfaches wie geniales Prinzip: Copy on Write. Beim fork() wird der Adressraum ja nur kopiert, die Adressräume von Eltern- und Kindprozess sind also direkt nach der Erstellung noch identisch. Daher werden die Adressräume auch nicht real kopiert, sondern die Speicherbereiche werden als »nur-lesbar« markiert. Versucht nun einer der beiden Prozesse, auf eine Adresse zu schreiben, bemerkt das Betriebssystem den Fehler und kann den betreffenden Speicherbereich kopieren – diesmal natürlich für beide schreibbar.
Die Prozesshierarchie
Familienbeziehungen
Wenn ein Prozess immer von einem anderen erzeugt wird, so ergibt sich eine Prozesshierarchie. Jeder Prozess – außer dem beim Systemstart erzeugten init-Prozess – hat also einen Elternprozess. So kann man aus allen Prozessen zur Laufzeit eine Art Baum mit init als gemeinsamer Wurzel konstruieren.
Eine solche Hierarchie hat natürlich gewisse Vorteile bei der Prozessverwaltung: Die Programme können so nämlich über bestimmte Syscalls die Terminierung samt eventueller Fehler überwachen. Außerdem war in den Anfangsjahren von Unix das Konzept der Threads noch nicht bekannt und so musste Nebenläufigkeit innerhalb eines Programms über verschiedene Prozesse realisiert werden. Dies ist der Grund, warum es eine so strenge Trennung von Prozess und Programm gibt und warum sich Prozesse selbst kopieren können, was schließlich auch zur Hierarchie der Prozesse führt.
Das Scheduling
Den nächsten Prozess auswählen
Nach der Prozesserstellung soll ein Prozess nach dem Multitasking-Prinzip abgearbeitet werden. Dazu müssen alle im System vorhandenen Threads und Prozesse nacheinander jeweils eine gewisse Zeit den Prozessor nutzen können. Die Entscheidung, wer wann wie viel Rechenleistung bekommt, obliegt einem besonderen Teil des Betriebssystems, dem Scheduler.
Als Grundlage für das Scheduling dienen dabei bestimmte Prozesszustände, diverse Eigenschaften und jede Menge Statistik. Betrachten wir jedoch zuerst die für das Scheduling besonders interessanten Zustände:
- RUNNING
Den Zustand RUNNING kann auf einem Einprozessorsystem nur je ein Prozess zu einer bestimmten Zeit haben: Dieser Zustand zeigt nämlich an, dass dieser Prozess jetzt gerade die CPU benutzt. - READY
Andere lauffähige Prozesse haben den Zustand READY. Diese Prozesse stehen also dem Scheduler für dessen Entscheidung, welcher Prozess als nächster laufen soll, zur Verfügung. - BLOCKED
Im Gegensatz zum READY-Zustand kann ein Prozess auch aus den verschiedensten Gründen blockiert sein, wenn er etwa auf Eingaben von der Tastatur wartet, ohne bestimmte Datenpakete aus dem Internet nicht weiterrechnen oder aus sonstigen Gründen gerade nicht arbeiten kann.
Prozesse wieder befreien
Wenn die Daten für einen solchen wartenden Prozess ankommen, wird das Betriebssystem üblicherweise über einen Interrupt informiert. Das Betriebssystem kann dann die Daten bereitstellen und durch Setzen des Prozessstatus auf READY diesen Prozess wieder freigeben.
Natürlich gibt es noch weitere Zustände, von denen wir einige in späteren Kapiteln näher behandeln werden. Mit diesen Zuständen hat nämlich weniger der Scheduler als vielmehr der Benutzer Kontakt, daher werden sie hier nicht weiter aufgeführt.
Prozesse bevorzugen
Weitere wichtige Daten für den Scheduler sind eventuelle Prioritäten für spezielle Prozesse, die besonders viel Rechenzeit erhalten sollen. Auch muss natürlich festgehalten werden, wie viel Rechenzeit ein Prozess im Verhältnis zu anderen Prozessen schon bekommen hat.
Der O(1)-Scheduler
Wie sieht nun aber der Scheduler in Linux genau aus? In der 2.6er-Kernelreihe wurde das Scheduling bis zum 2.6.23er Kernel im sogenannten O(1)-Scheduler wie folgt realisiert: Der Kernel verwaltete zwei Listen mit allen lauffähigen Prozessen: eine Liste mit den Prozessen, die schon gelaufen sind, und die andere mit allen Prozessen, die noch nicht gelaufen sind. Hatte ein Prozess nun seine Zeitscheibe beendet, wurde er in die Liste mit den abgelaufenen Prozessen eingehängt und aus der anderen Liste entfernt. War die Liste mit den noch nicht abgelaufenen Prozessen abgearbeitet und leer, so wurden die beiden Listen einfach getauscht.
Eine Zeitscheibe, in der ein Prozess rechnet, dauert unter Linux übrigens maximal 1/1000 Sekunde. Sie kann natürlich auch vor Ablauf dieser Zeit abgebrochen werden, wenn das Programm zum Beispiel auf Daten wartet und dafür einen blockierenden Systemaufruf benutzt hat. Bei der Auswahl des nächsten abzuarbeitenden Prozesses wurden dabei interaktive vor rechenintensiven Prozessen bevorzugt. Interaktive Prozesse interagieren mit dem Benutzer und brauchen so meist eine geringe Rechenzeit. Dafür möchte der Benutzer bei diesen Programmen eine schnelle Reaktion haben, da eine Verzögerung zum Beispiel bei der grafischen Oberfläche X11 sehr negativ auffallen würde. Der O(1)-Scheduler besaß nun ausgefeilte Algorithmen, um festzustellen, von welcher Art ein bestimmer Prozess ist und wo Grenzfälle am besten eingeordnet werden.
Der Completely Fair Scheduler
Seit Kernel 2.6.24 verwendet Linux den »completely fair scheduler«, CFS. Dieser Scheduler basiert auf einem einfachen Prinzip: Beim Taskwechsel wird der Task gestartet, der schon am längsten auf die Ausführung bzw. Fortsetzung wartet. Dadurch wird eine auf Desktop- wie auf Serversystemen gleichermaßen »faire« Verteilung der Prozessorzeit erreicht.
Bei vielen »gleichartigen« Tasks auf Serversystemen ist die Fairness offensichtlich. Auf Desktopsystemen mit vielen interaktiven Prozessen wird jedoch auch die Zeit berücksichtigt, die ein Prozess blockiert ist, weil er bspw. auf Eingaben des Benutzers oder auf Rückmeldung der Festplatte wartet. Ist ein solcher interaktiver Prozess dann lauffähig, wird er mit hoher Wahrscheinlichkeit auch zeitnah vom Scheduler gestartet, da er ja schon lang »gewartet« hat. Beim CFS entfällt somit die Notwendigkeit, über Heuristiken etc. festzustellen, ob es sich um einen interaktiven oder rechenintensiven Task handelt. Auch gibt es keine zwei Listen mehr, da alle Tasks in einer zentralen, nach »Wartezeit« geordneten Datenstruktur gehalten werden.
Details zur Priorisierung von Prozessen und zum Zusammenhang mit Scheduling erfahren Sie in Kapitel 26, »Prozesse und IPC«.
Beenden von Prozessen
Irgendwann wird jeder Prozess einmal beendet. Dafür kann es natürlich verschiedenste Gründe geben, je nachdem, ob sich ein Prozess freiwillig beendet oder beendet wird. Folgende Varianten sind zu unterscheiden:
- normales Ende (freiwillig)
- Ende aufgrund eines Fehlers (freiwillig)
- Ende aufgrund eines Fehlers (unfreiwillig)
- Ende aufgrund eines Signals eines anderen Prozesses (unfreiwillig)
Die meisten Prozesse beenden sich, weil sie ihre Arbeit getan haben. Ein Aufruf des find-Programms durchsucht zum Beispiel die gesamte Festplatte nach bestimmten Dateien. Ist die Festplatte durchsucht, beendet sich das Programm. Viele Programme einer grafischen Oberfläche geben dem Benutzer die Möglichkeit, durch einen Klick auf »das Kreuz rechts oben« das Fenster zu schließen und die Applikation zu beenden – auch eine Art des freiwilligen Beendens. Diesem ging ein entsprechender Wunsch des Benutzers voraus.
Fehler!
Im Gegensatz dazu steht das freiwillige Beenden eines Programms aufgrund eines Fehlers. Möchte man zum Beispiel mit dem gcc eine Quelldatei übersetzen, hat sich aber dabei bei der Eingabe des Namens vertippt, wird Folgendes passieren:
Listing 5.10 Freiwilliges Beenden des gcc
$ gcc -o test tset.c
gcc: tset.c: Datei oder Verzeichnis nicht gefunden
gcc: keine Eingabedateien
$
exit()
Damit sich Programme auf diese Weise freiwillig beenden können, brauchen sie einen Syscall. Unter Unix heißt dieser Aufruf exit(), und man kann ihm auch noch eine Zahl als Rückgabewert übergeben. Über diesen Rückgabewert können Fehler und teilweise sogar die Fehlerursache angegeben werden. Ein Rückgabewert von »0« signalisiert dabei »alles okay, keine Fehler«. In der Shell kann man über die Variable $? auf den Rückgabewert des letzten Prozesses zugreifen. Im obigen Beispiel eines freiwilligen Endes aufgrund eines Fehlers erhält man folgendes Ergebnis:
Listing 5.11 Rückgabewert ungleich Null: Fehler
$ echo $?
1
$
Wie aber sieht nun ein vom Betriebssystem erzwungenes Ende aus? Dieses tritt vor allem auf, wenn ein vom Programm nicht abgefangener und nicht zu reparierender Fehler auftritt. Dies kann zum Beispiel eine versteckte Division durch null sein, wie sie bei folgendem kleinen C-Beispiel auftritt:
Listing 5.12 Ein Beispielcode mit Division durch Null
#include <stdio.h>
int main()
{
int a = 2;
int c;
// Die fehlerhafte Berechnung
c = 2 / (a – 2);
printf("Nach der Berechnung.\n");
return 0;
}
Will man dieses Beispiel nun übersetzen, ausführen und sich schließlich den Rückgabewert ansehen, muss man wie folgt vorgehen:
Listing 5.13 Den Fehler betrachten
$ gcc -o test test.c
$ ./test
Gleitkomma-Ausnahme
$ echo $?
136
Böse Fehler!
Der Punkt, an dem der Text »Nach der Berechnung.« ausgegeben werden sollte, wird also nicht mehr erreicht. Das Programm wird vorher vom Betriebssystem abgebrochen, nachdem es von einer Unterbrechung aufgrund dieses Fehlers aufgerufen wurde. Das System stellt fest, dass das Programm einen Fehler gemacht und dafür keine Routine zur einer entsprechenden Behandlung vorgesehen hat – folglich wird der Prozess beendet. Einen solchen Fehler könnte ein Programm noch abfangen, aber für bestimmte Fehler ist auch dies nicht mehr möglich. Sie werden ein solches Beispiel im Abschnitt über Speichermanagement kennenlernen, wenn auf einen vorher nicht mit malloc() angeforderten Bereich des virtuellen Speichers zugegriffen und damit ein Speicherzugriffsfehler provoziert wird.
Kommunikation zwischen Prozessen
Jetzt müssen wir nur noch die letzte Art eines unfreiwilligen Prozessendes erklären: die Signale. Signale sind ein Mittel der Interprozesskommunikation (IPC), über die es in diesem Buch ein eigenes Kapitel gibt. Die dort beschriebenen Mechanismen regeln die Interaktion und Kommunikation der Prozesse miteinander und sind so für die Funktionalität des Systems sehr bedeutend. Ein Mittel dieser IPC ist nun das Senden der Signale, von denen zwei in diesem Zusammenhang für das Betriebssystem besonders wichtig sind:
- SIGTERM
Dieses Signal fordert einen Prozess freundlich auf, sich zu beenden. Der Prozess hat dabei die Möglichkeit, dieses Signal abzufangen und noch offene temporäre Dateien zu schließen, bzw. alles zu unternehmen, um ein sicheres und korrektes Ende zu gewährleisten. Jedoch ist für ihn klar, dass dieses Signal eine deutliche Aufforderung zum Beenden ist. - SIGKILL
Reagiert ein Prozess nicht auf ein SIGTERM, so kann man ihm ein SIGKILL schicken. Dies ist nun keine freundliche Aufforderung mehr, denn der Prozess bemerkt ein solches Signal nicht einmal mehr. Er wird vom Betriebssystem sofort beendet, ohne noch einmal gefragt zu werden.
Der Shutdown
Ein unfreiwilliges Ende wäre also der Empfang [Fn. Dieses Signal kann, wie gesagt, nicht abgefangen werden, aber der Prozess ist doch in gewissem Sinne der Empfänger dieses Signals.] eines SIGKILL-Signals. Beim Herunterfahren des Systems wird entsprechend der Semantik beider Signale auch meist so verfahren: Zuerst wird allen Prozessen ein SIGTERM gesendet, dann einige Sekunden gewartet und schließlich allen ein SIGKILL geschickt.
5.3.3 Implementierung

Im Folgenden geben wir einen kurzen Überblick über die Implementierung von Tasks und Threads im Linux-Kernel. Wir haben schon vereinzelt viele Details erwähnt, wenn diese gerade in den Kontext passten. In diesem Abschnitt möchten wir nun einige weitere Einzelheiten vorstellen, auch wenn wir natürlich nicht alle behandeln können.
Konzentrieren wir uns zunächst auf die Repräsentation eines Prozesses im System. Wir haben festgestellt, dass ein Prozess viele zu verwaltende Daten besitzt. Diese Daten werden nun direkt oder indirekt alle im Prozesskontrollblock gespeichert. Diese Struktur bildet also ein Programm für die Ausführung durch das Betriebssystem in einen Prozess ab. Alle diese Prozesse werden nun in einer großen Liste, der Prozesstabelle (engl. process table), eingetragen. Jedes Element dieser Tabelle ist also ein solcher Kontrollblock.
So ist's im Code
Sucht man diesen Kontrollblock nun im Kernel-Source, so wird man in der Datei include/linux/sched.h fündig. Dort wird nämlich der Verbund task_struct definiert, der auch alle von uns erwarteten Eigenschaften besitzt:
Listing 5.14 Beginn der task_struct im Kernel
struct task_struct {
volatile long state; /* –1 unrunnable,
0 runnable, >0 stopped */
struct thread_info *thread_info;
...
Status und Thread
In diesem ersten Ausschnitt kann man bereits erkennen, dass jeder Task (Prozess) einen Status sowie einen initialen Thread besitzt. Dieser erste Ausführungsfaden wird aus Konsistenzgründen benötigt, um beim Scheduling keine weitgreifenden Unterscheidungen zwischen Threads und Prozessen treffen zu müssen.
Auch zum Scheduling gibt es in dieser Struktur Informationen:
Listing 5.15 Informationen zum Scheduling
...
int prio, static_prio;
struct list_head run_list;
prio_array_t *array;
unsigned long sleep_avg;
long interactive_credit;
unsigned long long timestamp, last_ran;
int activated;
unsigned long policy;
cpumask_t cpus_allowed;
unsigned int time_slice, first_time_slice;
...
Der eigene Speicher
Natürlich hat auch jeder Task seinen eigenen Speicherbereich. In der Struktur mm_struct merkt sich der Kernel, welche virtuellen Adressen belegt sind und auf welche physischen, also real im Hauptspeicher vorhandenen Adressen diese abgebildet werden. Jedem Task ist eine solche Struktur zugeordnet:
Listing 5.16 Informationen zum Memory Management
struct mm_struct *mm, *active_mm;
Eine solche Struktur definiert nun einen eigenen Adressraum. Nur innerhalb eines Tasks kann auf die im Hauptspeicher abgelegten Werte zugegriffen werden, da innerhalb eines anderen Tasks keine Übersetzung von einer beliebigen virtuellen Adresse auf die entsprechend fremden realen Speicherstellen existiert.
Prozesshierarchie
Später werden in der Datenstruktur auch essenzielle Eigenschaften wie die Prozess-ID oder Informationen über die Prozesshierarchie gespeichert:
Listing 5.17 Prozesshierarchie
pid_t pid;
...
struct task_struct *parent;
struct list_head children;
struct list_head sibling;
...
Diese Hierarchie ist also so implementiert, dass ein Prozess einen direkten Zeiger auf seinen Elternprozess besitzt und außerdem eine Liste seiner Kinder sowie eine Liste der Kinder des Elternprozesses. Diese Listen sind vom Typ list_head, der einen Zeiger prev und next zur Verfügung stellt. So kann bei entsprechender Initialisierung schrittweise über alle Kinder beziehungsweise Geschwister iteriert werden.
Listing 5.18 Informationen über den Benutzer
...
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
...
Die Rechte
Natürlich sind auch alle Benutzer- und Gruppen-IDs für die Rechteverwaltung im Task-Kontrollblock gespeichert. Anhand dieser Werte kann bei einem Zugriff auf eine Datei festgestellt werden, ob dieser berechtigt ist.
Mehr über die Rechteverwaltung erfahren Sie in den Kapiteln 6 und 13.
Natürlich finden sich auch alle bereits angesprochenen Statusinformationen des Tasks in der Datenstruktur. Dazu gehören unter anderem seine geöffneten Dateien:
Listing 5.19 Offene Dateien und Co.
...
/* file system info */
int link_count, total_link_count;
/* ipc stuff */
struct sysv_sem sysvsem;
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* namespace */
struct namespace *namespace;
/* signal handlers */
struct signal_struct *signal;
struct sighand_struct *sighand;
...
};
... und der ganze Rest
In diesem Ausschnitt konnten Sie auch einige Datenstrukturen für die Interprozesskommunikation erkennen, beispielsweise eine Struktur für Signalhandler, also die Adressen der Funktionen, die die abfangbaren Signale des Prozesses behandeln sollen.
Mehr zur Interprozesskommunikation finden Sie in Kapitel 26.
Ebenso haben auch Threads einen entsprechenden Kontrollblock, der natürlich viel kleiner als der eines kompletten Tasks ist.
Listing 5.20 Thread-Strukturen
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
struct thread_info {
struct task_struct *task; /* main task structure */
...
unsigned long status; /* thread flags */
__u32 cpu; /* current CPU */
...
mm_segment_t addr_limit;
/* thread address space: 0-0xBFFFFFFF for user-thread
0-0xFFFFFFFF for kernel-thread */
...
unsigned long previous_esp;
/* ESP of the previous stack in case of nested
(IRQ) stacks */
...
};
An den Strukturen in Listing 1.20 kann man nun sehr schön die reduzierten Eigenschaften eines Threads sehen: Stack, Status, die aktuelle CPU und ein Adresslimit, das die Abgrenzung zwischen Threads des Kernels und des Userspace leistet. Außerdem ist ein Thread natürlich einem bestimmten Task zugeordnet.
Datenstrukturen versus Code
Auch wenn Sie jetzt nur einen kurzen Blick auf die den Prozessen und Threads zugrunde liegenden Datenstrukturen werfen konnten, sollen diese Ausführungen hier genügen. Natürlich gibt es im Kernel noch sehr viel Code, der diese Datenstrukturen mit Werten und damit mit Leben fällt – die Basis haben Sie jedoch kurz kennengelernt.
Mehr dazu gibt es natürlich im Quellcode des Kernels.
Kommen wir nun jedoch zum Speichermanagement. Wir haben dieses Thema schon kurz bei der Besprechung der Speicherhierarchie und der Aufgabe des Stacks angeschnitten und wollen uns nun näher mit den Aufgaben sowie den konkreten Lösungen in diesem Problemkreis beschäftigen.
Ihr Kommentar
Wie hat Ihnen das <openbook> gefallen? Wir freuen uns immer über Ihre freundlichen und kritischen Rückmeldungen.

 Jetzt
bestellen
Jetzt
bestellen





